
Introduction
Large Language Models (LLMs) have significantly advanced natural language processing, providing task-agnostic foundations for wide-ranging applications across multiple domains (Ling et al. 2025). These AI systems, increasingly adopted in industries such as healthcare, finance and law, are trained on massive datasets and can generate and translate human language while performing functions tailored to specific needs.
In healthcare, LLMs have been explored for diverse applications, with providers integrating them into different stages of their workflows. Recent studies on applications of LLMs in healthcare report their use in diagnostics, clinical documentation, education and research (Maity and Saikia 2025; Meng et al. 2024; Wang and Zhang 2024). Evidence of LLM adaptation for low-resource and African contexts is beginning to emerge. Alhanai et al. (2024) demonstrated improvements in LLM performance for eight African languages through fine-tuning and cultural adjustments, highlighting the feasibility of deploying these models in multilingual and resource-constrained settings.
However, the effectiveness of LLMs in healthcare depends fundamentally on the quality and representativeness of their training data. LLM training datasets are typically drawn from both public and private sources, including web pages, books, research articles, videos and code repositories (Baack 2024), where many processes behind data construction are opaque despite efforts toward transparency (Hutchinson et al. 2021; Gebru et al. 2021; Rostamzadeh et al. 2022). In high-stakes healthcare settings, accuracy and equity must be safeguarded. LLMs trained on incomplete, biased or low-quality data risk amplifying medical inaccuracies or misrepresenting populations.
The challenge is particularly acute in resource-constrained settings, where models may be trained on data that underrepresents local disease burdens, languages or clinical practices. Research on LLMs in healthcare shows persistent imbalances in representation where studies and datasets are produced in high-income countries, overlooking local realities (Restrepo et al. 2024). Evidence also indicates that LLMs can reproduce demographic biases in medical recommendations, favouring higher income while underserving marginalized populations (Omar et al. 2025). Few studies examine LLM adoption in low-resource healthcare settings, particularly in contexts characterized by high patient volumes and limited support for frontline healthcare workers such as nurses.
These findings underscore widespread inequalities in both the creation and application of LLMs in healthcare. DeWitt Prat et al. (2024) advocate for participatory research and ethnography in Africa to “decolonize LLMs,” emphasizing that widely deployed models risk echoing and extending colonialist practices if they do not support African languages and social practices. Because clinical decisions entail patient-safety, equity, and accountability implications, context-aware evaluation is required. At the same time, there is a growing concern from healthcare workers about potential displacement of human care by AI (Akingbola et al. 2024; Rony et al. 2024), reinforcing the need for frontline-centric approaches (Panch, Mattie, and Atun 2019; Templin et al. 2025).
Kenya has expanded its health workforce, yet nurse density remains about 2.23 per 1,000, below the WHO threshold of 4.45 per 1,000 (WHO, 2016, 2020; Nursing Council of Kenya 2024). In understaffed settings, nurses routinely bridge multiple clinical roles, with workload and quality pressures (Rosser et al. 2022; Mbuthia et al. 2023). These realities motivate evaluating how LLM decision support can aid nursing practice.
Responsible integration of LLMs into healthcare requires systematic evaluation of their safety, reliability and fit within clinical workflows, as clinicians’ trust and adoption depend as much on workflow alignment as on technical accuracy (Chang et al. 2024; Obong’o et al. 2025; Denecke, 2024). Benchmark datasets are central to these evaluations because they provide structured ways to compare model performance, yet their design also determines which clinical challenges and patient groups receive attention (Kwiatkowski et al. 2019; Panch et al. 2020; Mincu and Roy 2022). To avoid privileging convenience over clinical relevance, benchmarks should be designed with clear principles: they need to be large and technically rigorous, include human validation and reflect the diversity of populations, settings and practical realities where LLMs will be deployed (Meng et al. 2024; Al Garadi et al. 2025; Myung et al. 2024; Sourlos et al. 2024).
Against this backdrop, the present study employs ethnographic techniques within a Human-Centred Design (HCD) framework to generate PHC scenarios and questions for context-specific data. HCD is a problem-solving approach that involves developing a deep understanding of the people you are designing for or with (PATH 2022). Applying HCD principles in benchmark dataset creation seeks to ensure that AI tools are considered a method to genuinely align with users’ needs and values, as emphasized in both academic literature and practitioner guidance (Bai et al. 2024; Bhutani 2025). Using participatory methods, we explore when and how nurses seek guidance and support during routine care. Nurses shared scenarios and formulated questions based on their workflows, offering insight into their real-time decision-making needs.
Community engagement has been largely absent in AI healthcare research, with one scoping review finding less than 0.2% of studies reporting meaningful community involvement (Loftus et al. 2024). This absence undermines trust and relevance in AI systems, as scholars point out that without strong participatory foundations, AI tools risk falling short on transparency and ethical alignment (Delgado and Saenz 2023). Evidence from humanitarian settings shows that involving communities directly in AI tool design ensures technology responds to local realities and urgent needs, a principle that applies equally to healthcare contexts (Berditchevskaia, Malliaraki, and Peach 2020). Research highlights both opportunities and challenges in participatory AI design (Birhane et al. 2022) and proposes new frameworks and solution-oriented methods that move beyond traditional approaches (Hossain and Ahmed 2021; Maas 2024; Parthasarathy et al. 2024). This study demonstrates how these participatory approaches can be practically highlighted, implemented with frontline healthcare providers’ experiences and to collect locally applicable data to inform further research and tool development. The aim of this paper is to describe the co-design of scenarios and questions. Results on model performance are reported in a companion paper.
Methodology
Case Study Design
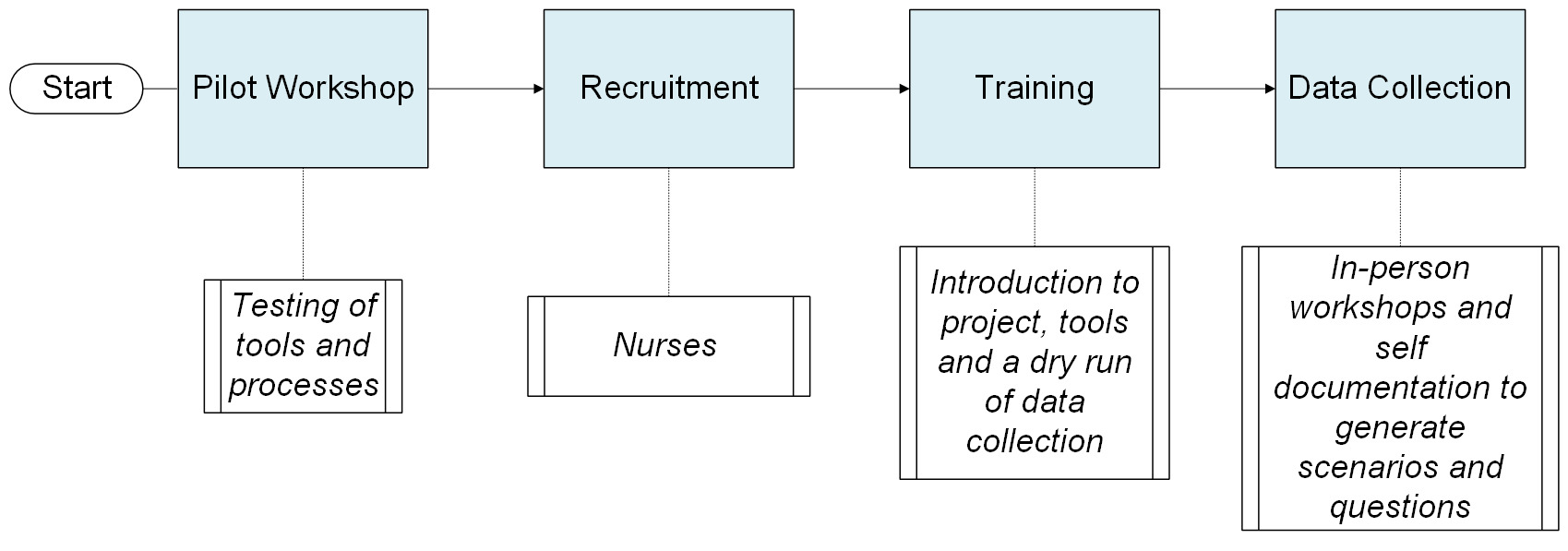
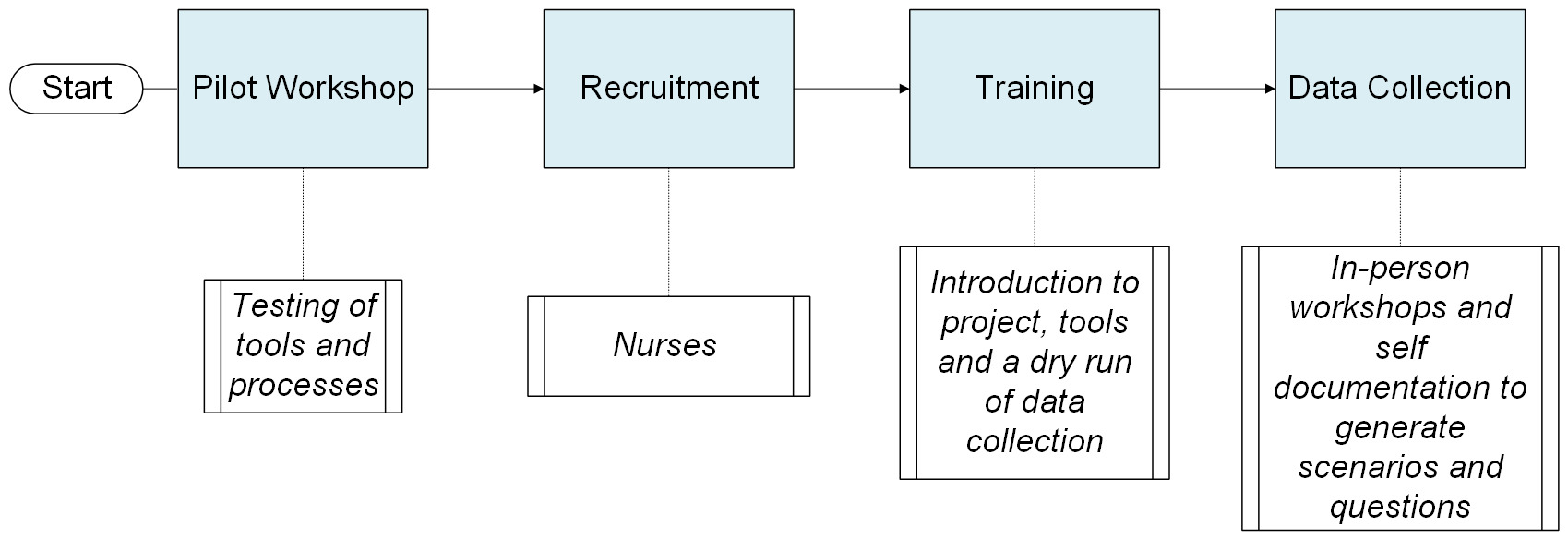
We used a multi-phase design. An initial ethnographic and human-centred design (HCD) foundation informed our adaptation of the SBAR (Situation, Background, Assessment, Recommendation/Request) clinical communication tool for scenario capture and guided technical integrations to preserve linguistic and cultural cues. Following a pilot workshop, we trained nurses and incorporated cultural probing to support self-documentation of real-world clinical scenarios through text and audio. Data collection was done through structured workshops and independent reflection, allowing nurses to share experiences in their own time and words.
Study Setting and Context
The human-centred design case study was conducted over three months (September- November) in 2024 across Kiambu, Kakamega and Uasin Gishu counties in Kenya, representing the central, western and Rift Valley regions, respectively. This geographic diversity provided an opportunity to gather medical scenarios and questions from nurses across various service contexts within Kenya’s health system.
-
Kiambu County: A peri-urban area bordering Nairobi County with a well-established network of health facilities.
-
Kakamega County: A predominantly rural area with high population density where healthcare access varies due to infrastructure challenges.
-
Uasin Gishu County: A semi-urban area with mixed rural and urban populations, especially in Eldoret town, featuring strong health infrastructure due to the presence of the Moi Teaching and Referral Hospital.
Methodological Innovation
Our approach centres provider voices and embeds ethnographic methods within a human-centred design framework to produce a dataset that is inclusive, representative and contextually grounded. English, an official language in Kenya, was selected as the primary language for data collection, informed by Kenya’s nursing education and clinical training practices, which are primarily conducted in English. Documentation of medical files is also done in English, ensuring consistency in medical terminology and alignment with professional practice. Our adaptation of the SBAR framework represents an ethnographic innovation in AI development. Traditionally used for clinical communication, SBAR was reimagined as a tool for eliciting the nurses’ lived experiences and knowledge needs in a structured, familiar format while preserving their idiolect within the final dataset.

Dataset Scope and Target Sample Size
The objective was to collect over 5,000 scenarios and questions from three healthcare settings to contribute to a benchmark dataset. This target number was set to ensure the dataset covers the diversity of primary healthcare and strengthens the reliability of LLM evaluation results while maintaining feasibility for curation and high-quality annotations. The objective of this approach was to capture a wide range of patient scenarios in the selected geographies, thus enhancing both representativeness and localization. Questions were framed as clinical requests, clarifications, or additional information that nurses would typically seek to proceed with patient care. Each nurse individually formatted questions after outlining all relevant patient details using the SBAR framework to reflect the types of inquiries that arise in real-time decision-making. Examples of nurse-generated scenarios presented verbatim in SBAR format are shown in Tables 1, 3, 4 and 5.
Pilot Workshop
We conducted an in-person pilot workshop with eight nurses to test our messaging in preparation for training and data collection to ensure the nurses had the proper guidance to generate scenarios and questions. The nurses tended to list the questions they ask patients during visits (e.g., record-keeping) rather than questions they themselves need answered to make clinical decisions. This observation indicated that our messaging was unclear. We therefore reframed the task explicitly around clinician information needs, introducing the prompt: “What questions do you have before making a decision for this patient?” and emphasising that questions should follow the patient history rather than duplicate it.
To further guide nurses in scenario and question generation, we conducted a journey mapping exercise. Nurses outlined a typical day of service provision, noting the key moments in their workflow, their goals at each stage and the pain points they encountered. Within each key step, we then asked the nurses to share an example of a patient visit. For instance, during triage, they described a typical case from when a patient arrived through to treatment or referral, including what was going on, how the patient appeared and what followed. This process kept examples anchored in their own workflows and care settings (see Table 2). During discussions, nurses identified their motivators and pain points, which served as prompts to encourage sharing of real cases where they had experienced those challenges or achievements. For example, when nurses mentioned successful management of a patient’s condition as a motivator, we asked them to provide typical examples of times when they felt they had successfully managed a patient.
Since examples were initially shared in an unstructured format, the research team worked with the nurses to break them down into SBAR-based scenarios and explicit questions. Collaborative editing helped nurses understand, using their own experiences, what constituted a scenario versus what formed a question. The outputs informed both the tools and the facilitation used in the main workshops.
We tested both writing and audio recording for documentation. Nurses generally preferred audio, but most found it helpful to take notes first before recording their scenarios and questions. Their notetaking process was possible due to nurses taking turns, giving peers time to reflect and draft ahead of their turn. In addition, our initial hypothesis that nurses could generate 100 questions in five hours (a one-day workshop) was revised to 30–40 scenarios, as nurses found it challenging to reach the target and quality diminished over time in their attempt to reach the target.
The pilot workshop was designed to create an open and reflective space where participants could share their concerns and reflect on their professional knowledge needs. This approach encouraged nurses to look inward and articulate areas where they experienced challenges and required support. Rather than solely focusing on patient queries, they were able to voice over areas of uncertainty and areas of decision-making during their workflows.
Recruitment and Training
After refining the training language and tools, we recruited 145 nurses from the three counties via county health management teams, supplemented by peer referral and hospital contacts. We sampled across facility levels, competencies, and years of experience to ensure diversity.
The recruited nurses attended half-day training sessions in each county incorporating lessons from the pilot. We aligned on project goals with refined language, practised using the SBAR tool to structure scenarios and questions and conducted group feedback sessions where nurses could practice asking questions based on their needs before moving to solving the challenge.
To ensure the nurses’ thought processes were grounded in their lived experiences and workflows, scenario and question examples were only provided as the final resort. Once nurses understood this foundation, they were then given the SBAR framework to guide them in structuring their scenarios.
Following the learning and practice sessions, nurses participated in a dry run simulating the actual data collection workshop. The nurses were placed in groups of 4–6 and each nurse took turns verbally sharing their scenarios and questions with audio recording done on Kobo Toolbox (an open-source digital data collection platform), with the help of a rapporteur. During the dry run, each nurse shared two scenarios to get a sense of how one full cycle of scenario sharing would transition to the other. The dry run established timing and roles; the same groups participated in the actual data collection the following day.
Data Collection Workshops
In each county, data collection started immediately after the training. Nurses were grouped into teams of 4–6, mirroring their training groups. Within each group, nurses took turns recording their scenarios using audio while others prepared their narratives and questions in written notes. This setup allowed rapid successive recording of multiple scenarios and allowed uncertain participants to draw inspiration from peers.
Scenario documentation followed the SBAR framework and was pre-loaded into Kobo Toolbox. Kobo Toolbox enables the design of structured surveys, offline data capture and secure storage and export of responses. Each group had a rapporteur who captured the audio using a simple record-and-stop function within the Kobo app. As nurses became more familiar with the process, some chose to document independently using a direct Kobo link sent to their devices, which allowed them to step away from the group to record their scenarios privately. The self-documentation process laid the foundation for continued data collection through online contributions after the in-person workshops.
To stimulate scenario generation, we provided a non-exhaustive list of common disease areas encountered in nursing derived from the Kenya MOH 711A form (a national reporting tool that captures routine facility-level data on common diseases and service utilization). This list served as a prompt when participants felt stuck rather than prescriptive guidance and nurses were encouraged to prioritize their own clinical experiences.
Each participant was encouraged to generate 30–40 questions during the workshop based on the insights and experience from the pilot testing and training workshop. While the average contribution was around thirty questions per nurse, a few reached the upper target. Rapporteurs emphasized quality over quantity, encouraging nurses to prioritize authenticity and relevance. Kobo Toolbox enabled seamless data capture both online and offline, supporting flexibility across all settings. In one county, the participant contributed ten scenarios in written format during the workshop, with additional written scenarios submitted over the following week through the rapporteur, who compiled them.
The SBAR framework guided participants through each step, starting with first outlining the situation, highlighting how the patient presents during a visit and allowing the nurse to capture information from observation and typical details such as patient demographics. Next, the patient’s background information or chief complaints were collected, including sharing any context related to the symptoms or relevant information needed to understand and evaluate the patient’s situation. Nurses then described their clinical information-gathering process, including examinations or tests conducted, before formulating questions where they would typically seek guidance on diagnosis or treatment decisions.
Virtual Data Collection
After each in-person workshop, nurses were invited to continue contributing scenarios and questions online. Using a preloaded SBAR framework on Kobo Toolbox, they could self-document and submit entries either as written text or audio recordings.
This phase lasted seven days, with nurses encouraged to submit as many questions as possible, up to a maximum of 100. Based on earlier feedback, this setup offered greater flexibility, enabling more thoughtful contributions. Nurses were added to county-specific WhatsApp groups where updates, reminders and troubleshooting support were provided throughout the week.
While not all nurses were able to participate in the online follow-up due to competing responsibilities, those who did generally contributed more questions than they had during the in-person sessions. The hybrid approach, combining structured workshops with asynchronous digital submissions, proved responsive to participants’ contexts while maintaining methodological rigor. It also highlighted the potential of digital platforms for supporting ethnographic data collection. Figure 2 summarizes the data collection.
Question Analysis
A random sample of 200 scenarios and their associated questions was reviewed to identify recurring patterns. Similar questions were clustered, and the emerging categories were refined. The resulting patterns were consolidated into thematic categories.
Ethical Considerations
This study received ethical approval from Maseno University IRB number: MSU/DRPI/MUERC/00899/20. All participants were informed about the purpose of the study, their right to withdraw at any time and how their data would be used. Written informed consent was obtained prior to participation. To protect confidentiality, all personal identifiers were removed from the data and scenarios were reviewed to ensure anonymity. Audio recordings were securely stored and transcribed using TurboScribe, with access limited to the research team. Participation was voluntary and care was taken to ensure that no harm came to participants during or after the study. The use of AI tools in data processing was conducted in accordance with ethical guidelines to maintain data integrity and privacy.
Findings
A total of 7,606 scenarios with questions were collected from 145 nurses (see county breakdown in Table 6).
The study involved 145 nurses across the three counties (See table 7), primarily from Kakamega (42.76%) and Uasin Gishu (40.69%) and less from Kiambu (14.48%). Due to close proximity to these main counties, a few nurses came from Bungoma (0.69%) and Elgeyo Marakwet (1.38%) as part of the Uasin Gishu workshop. Of the total, 117 (80.69%) were women and 28 (19.31%) were men, reflecting the global and national gender trends in nursing (WHO, 2020; Kenya Health Workforce Report, 2016).
In terms of professional roles, the majority were PHC nurses (76.55%), only 13.79% served as senior nurses, suggesting a workforce focused on direct patient care (See Table 8). Experience among the nurses ranged from one to thirty-eight years, with an average of 13.56 years, providing a diverse mix of expertise. Regarding educational qualifications, 63.45% hold diplomas, highlighting the emphasis on practical training. 107/145 (74%) of these nurses worked in mid-tier healthcare facilities, such as health centres and sub-county hospitals.
From the sampled scenarios, the range of clinical questions raised was broad, with recurring themes in diagnostic uncertainty, patient history interpretation and treatment options in resource-constrained settings. While these clinical categories were prominent, a substantial number of questions addressed non-clinical concerns. This thematic diversity highlights the multifaceted nature of decision-making in real-world contexts. Topics included logistical barriers, social and emotional factors, administrative processes and ethical considerations (See table 9). The scenarios and corresponding questions shared by participants point to a strong demand for decision-support resources that reflect the complexity of real-world clinical environments. Rather than textbook-style cases, the data suggests a preference for tools that accommodate uncertainty, incomplete information and variability in local contexts.
Thematic Analysis of Questions Asked within the Scenarios
The table below outlines examples of high-level themes highlighted within the questions. Some questions may underscore multiple themes. The themes presented in this paper are derived from a sample of the scenarios.
Insights from Scenario and Questions Sharing
About half of the nurses for each workshop arrived at the workshop with pre-written scenarios in their notebooks. This early preparation followed guidance from the earlier dry-run session, where participants were encouraged to reflect on clinical situations in advance. This proactive engagement contributed to a smooth start and early momentum in scenario sharing.
The use of audio recordings gave nurses the freedom to share their experiences without pressure to summarize or follow rigid templates. Scenario narratives varied in length and depth. Some were shared with detailed context, while others remained brief and to the point. In many cases, nurses diverged from the expected SBAR format, sometimes introducing clinical questions early in the scenario or integrating them into broader reflections. The audio recordings captured these nuances including hesitations, emotions and contextual reasoning, offering richer insight into the nurses’ clinical thinking.
All nurses in each workshop expressed that the activity was challenging, noting that it was one of the first times they had been asked to externalize and articulate their internal clinical thought processes. Many shared that the experience helped them recognize the types of questions and judgments they make instinctively or subconsciously while delivering care.
More than half of the nurses also found it difficult to generate their initial individual target scenarios. This challenge stemmed from the fact that they typically resolved issues quickly and independently in their daily work, which made it challenging to recall or share questions that could inform scenarios. This insight helped us adjust the language we used, to which end we encouraged nurses to share questions even in situations where they had ultimately answered them on their own. Consequently, some nurses suggested generating questions online to provide more time for inspiration.
Insights on Workshop Facilitation
-
The team adopted simplified language when introducing the project, emphasizing “clinical decision support” rather than complex terms like AI or LLM. Framing the workshop to build knowledge systems that could potentially help nurses in African contexts helped generate buy-in.
-
The prompt, “What questions do you have before making a decision for your patient?” effectively anchored the concept of question generation among participants."
-
Trained facilitators were advised not to use SBAR abbreviations when introducing the tool, but instead to present the full terms situation, background, assessment and request. This move aimed to minimize risk of misinterpretation based on participants’ pre-existing understanding of the format and use of the tool.
-
When introducing the scenario outline, facilitators asked participants to draft scenarios and related questions before showing examples. This approach surfaced early gaps and allowed for real-time clarification.
-
Most nurses quickly grasped the process of question generation during the in-person workshops. However, output slowed considerably after about ten scenarios. By the twentieth scenario, many were visibly fatigued or stalled. Facilitators encouraged participants to continue making submissions of even very simple scenarios to maintain momentum, yet they stressed quality over quantity.
-
Group work proved helpful. In groups of two to three, nurses who understood the process helped others adapt. This peer-learning effect reinforced the potential value of small group facilitation for future iterations.
-
Participants were reminded to submit a mix of simple and complex scenarios. Some initially assumed that only difficult clinical situations were being sought.
-
Fatigue emerged as a critical challenge. Facilitators encouraged teams to take breaks as needed, recognizing that the repetitive nature of the task affected engagement levels over time.
Documentation Process
-
Some rapporteurs were unable to keep up with the speed of verbal input; others worked from audio recordings rather than live typing.
-
Some rapporteurs allowed nurses to document several scenarios before verbally sharing them for entry into Kobo. This writing phase appeared to support deeper reflection and improved quality in subsequent scenarios.
-
There was a clear need for rapporteurs to be well-versed in the process, including expected inputs and how to guide participants.
-
Some participants posed clinical questions they would ask patients (e.g., “What is their LMP?”) that required clarification from facilitators regarding the purpose of the task.
-
Language use during data collection presented challenges, as some participants interspersed Swahili into their scenarios and diverse accents occasionally affected clarity in the recordings. To support transcription accuracy and consistency, rapporteurs were reminded to encourage the use of English throughout the sessions.
General Feedback from Nurses
Initial engagements with nurses revealed a strong culture of self-reliance in clinical decision-making. As one participant noted, “We rarely have unanswered questions; we always find solutions.” This norm prompted facilitators to clarify that the project was also interested in understanding the clinical questions nurses grapple with even when they eventually resolve them independently.
Additionally, some participants questioned the involvement of clinicians in the process, asking questions like, “Why are answers to our questions being provided by clinicians?” The team clarified that while clinicians play a role in the answer phase, the design process welcomes both nurse- and clinician-generated input in order to reinforce the relevance of nurses’ voices in clinical decision-making.
Discussion
We co-designed and curated a nurse-generated PHC dataset from three Kenyan counties using a human-centred design approach. By eliciting scenarios with an adapted SBAR structure, the dataset captures decision points that nurses face in routine care, including clinical management, diagnostics, referral, communication and resource constraints. This study addresses critical gaps in contextual awareness and the representation of frontline realities in the potential use of LLMs in healthcare (Hamid and Brohi 2024; Talukdar and Biswas 2024). Our participatory HCD approach, specifically involving frontline nurses, directly tackles the pervasive issue of LLM training and evaluation lacking grounding in actual clinical workflows and resource-constrained PHC settings. The scenarios and questions collected contribute a unique benchmark dataset for testing and evaluating LLMs for PHC.
The participatory approaches used in this study anchored the dataset in the lived experiences of nurses. Beyond ensuring contextual relevance, these methods fostered peer learning and mutual support throughout the process. Audio recording allowed participants to create rich, unfiltered scenarios that preserved the natural flow of nurses’ thought and decision-making processes in real-time, though it required significant effort to clean and organize. Notably, the recordings register how clinical decision-making often begins earlier than expected; sometimes during the background information stage, before any assessment is performed. This observation highlights the potential need for decision-support tools that engage nurses at earlier stages of the care process. This participant-driven approach highlights the importance of flexible methodologies when designing clinical decision support tools intended to operate in dynamic and resource-constrained settings (Anibal et al. 2025).
The contribution is significant given the central role of benchmarks: they address limitations LLMs often suffer from such as outdated knowledge, lack of contextual awareness and bias in recommendations (Denton et al. 2020). These lacunas are amplified in low-resource settings, where local disease burdens and infrastructural constraints are unaccounted for in LLM training data. The dataset generated in this project responds with a clinically grounded benchmark that captures the realities of PHC in Kenya and enables evaluation across both technical accuracy and clinically meaningful dimensions such as information quality, reasoning, clarity of expression and potential safety implications (Tam et al. 2024).
Strengths
Involving nurses in the early stages of dataset creation provided an unexpected benefit: it created space for nurses to reflect on their own clinical reasoning. We mapped nurses’ journeys and workflows to adapt the SBAR framework, which then guided nurses in capturing key elements of clinical scenarios and follow-up questions. The mapping process brought out pain points in their workflows and informed how they would ask questions based on what information they needed to provide care. Some participants noted the challenge of articulating their decision-making processes, underscoring a gap in how this thinking is externalized in routine care. This finding has implications for tool design, professional development and reflective practice.
Our focus on nurses as primary dataset contributors is also significant, as their voices are often excluded from AI development. Most clinical decision-support tools are developed using physician-centred data and workflows, as evidenced by scoping reviews showing a scarcity of tools designed for non-physician users (Harada et al. 2021), field studies exposing mismatches with local nurse practices (Wang et al. 2021) and reviews noting a lack of nursing-specific AI tools (Wei et al. 2025). Nurses make critical real-time decisions, often in high-pressure, low-resource settings. By showing how nurses’ reasoning can be captured and organized, this study helps bridge the gap in tool development.
This study also highlights the need to incorporate community perspectives beyond healthcare providers. Tools supporting care delivery across health system levels must account for community values and patient expectations, especially where AI trust is nascent or non-existent (d’Elia et al. 2022; Dankwa-Mullan 2024).
Limitations
This study has six key limitations. First, data collection occurred in only three Kenyan counties and findings may not be generalizable across Kenya or other health systems. Expanding geographic coverage in future studies would strengthen contextual relevance and tool applicability. Second, thematic analysis focused on identifying broad recurring themes of the questions rather than subthemes, in a sample data size. As a result, some finer distinctions in knowledge requirements may not have been highlighted for the whole dataset. Incorporating themes for all the questions in future analyses could provide a more detailed map of the specific areas where frontline healthcare providers shared questions on. Third, the dataset contains only text-based data and does not incorporate multimodal data such as images or clinical charts. In real-world PHC settings, decision-making often involves interpreting visual cues (e.g., skin and eye appearance) and reviewing patient records. The absence of these modalities may constrain the dataset’s ability to fully represent clinical complexity and limit the scope of LLM evaluation to textual reasoning. Future iterations of this dataset could benefit from integrating diverse data types to better reflect these. Fourth, the use of English as the primary language for data collection may have constrained the way scenarios and questions were expressed. While participants were encouraged to use English, it is possible that some nuances typically conveyed in Kiswahili or local dialects were not fully captured. Fifth, data collection modalities varied across counties, with one county using text-only documentation and another audio-only. This variation reflected logistical considerations, including facilitator capacity and available infrastructure. Sixth, participant compensation may have influenced participation, which should be considered when interpreting the findings.
Conclusion
This study demonstrates how participatory methods can create contextually grounded benchmark datasets. By grounding the data in the experience of nurses in the Kenyan context, the results of this case study highlight the diverse nuances of what providing care in PHC entails, with scenarios spanning beyond clinical questions. Drawing on nurses’ workflows and lived experiences, the process ensured that the resulting data reflected real-world complexity and contextual relevance elements often overlooked in “general-purpose” datasets. This dataset may be used to benchmark LLMs for primary health care, characterise model failure modes and inform safer evaluation protocols in low-resource settings, thereby strengthening the currently limited evidence base on LLM evaluation in such contexts (Rutunda et al. 2025).
Future studies should expand geographical reach and explore additional methods such as asynchronous or digital contributions to complement in-person workshops and reduce fatigue, especially when building large datasets. Overall, this work highlights the essential role of HCD in shaping AI tools that are ethical, useful and responsive to the realities of care in diverse settings.
Acknowledgements
We recognize with deep appreciation the late Brian Taliesin, whose insight, generosity of thought and intellectual leadership were instrumental to both the study and the development of this paper. We remain immensely grateful for the commitment and dedication he brought to the project.
We gratefully acknowledge the support of Moi University (Kenya) for their contribution to data collection in this study.