Introduction
As research practitioners, we are often asked: how are we integrating Artificial Intelligence (AI) into our workflows—how are we adapting our practices to take advantage of the affordances AI provides? At the same time, design research itself is at an inflection point. Product owners, research managers, and budget-setters are going back and forth over whether it’s worth the time and money. Do we need to do research to acquire the intelligence to make every decision? Likely, no. So then what kind of research does create value—and for what purpose—particularly in an era when budgets are tight? What kind of questions need less investment and can rely on AI to answer them, and which questions still require a team to go out and collect data from the world?
With the rise of the public availability and access to generative AI, we are seeing tools emerge that promise to resolve the tension between intelligence and constraints. These products seek to augment research workstreams from planning and ideating to auto-transcription and sensemaking. Perhaps the most radical version of this shift towards AI-powered automation in applied social research is the displacement of research participants with AI-generated, synthetic counterparts. This is not a hypothetical future. The market research and UX research industries are being disrupted. It is our job as practitioners to play a leading role in shaping the future of the industry and setting best practices for AI-driven tools and their “human-led” counterparts.
AI’s capabilities are growing by the minute, so the mindsets of what a researcher can or should do with this technology must evolve alongside. Therefore, we don’t intend to speculate on what the researcher’s toolkit would look like in the future; instead, we examine the fundamental principles of how AI is designed and how that affects early-stage innovation, tying the inherent outcomes defined by these principles with their implications for designing products and experiences for humans. While we recognize AI, synthetic data, and AI-generated users have the potential to enhance aspects of the design and innovation process, particularly around desk research and storytelling, we show that they are unable to provide key ingredients that come from in-context research, which is critical for this type of work. Specifically, we argue that by bypassing in-context research, especially for complex design challenges without established behavioral patterns, teams fail to gather the rich learning necessary for breakthrough products and fail to develop a shared team intelligence.
In many ways, Design Research and associated disciplines (User Experience Research, Service Design, etc.), behave like any other business function within an organization. The size of the business unit scales up and down with the need, and there is an effort for continuous improvement in the operations of the unit. There is pressure to deliver, not just in the quality and impact of the output, but in the efficiency in which the work gets done, especially in a field whose relationship with revenue is often indirect. This is not new. EPIC’s 2009 conference was on this very topic of the value of research in business and contributions from that year’s proceedings feel all too relevant in today’s moment (Lombardi 2009; Rejón 2009; Zelt 2009). Nevertheless, some things have changed in the past 15 odd years. Continuous learning research and “rapid research” programs have become more of the norm (R. Lee 2025). Research has been “democratized” within many organizations (Levin, n.d.). Perhaps most notably, generative AI (hereafter, Gen AI) research tools have taken off either in the tools we already use or in “AI-native” tools that seek to streamline the research process.
New tools utilizing Gen AI promise to resolve the tension between delivering intelligence, while working within (or indeed, removing) constraints. These products seek to augment research workstreams from planning and ideating to auto-transcription and sensemaking. Perhaps the most radical version of this shift towards AI-powered automation in applied social research is the displacement of research participants with AI-generated, synthetic counterparts.
A few months before ChatGPT was released to the public, Argyle et al. (2022) observed that Large Language Models (LLMs), with proper conditioning that unearths their “algorithmic bias” could be used to reproduce complex mindset patterns in US population-based subgroups across demographic attributes, most notably, partisan affiliation. In user and market research, this was interpreted as an ability of LLMs to offer insights that would typically require lengthy research with human subjects, and soon after, numerous tools and companies emerged with the premise of user research without the tedious and costly aspects (Brand, Israeli, and Ngwe 2023, revised July 2024).
The integration of AI into the workflow has been a challenging subject across many industries. AI’s entry into the design research workflow perhaps feels more pronounced since centering humans and human needs forms the basis of our practice.[1] In this paper, our goal is to interrogate the value of new tools with an eye on the future, and through the lens of design research process and impact. We evaluate the benefits and risks of these new technologies, while also allowing ourselves to occasionally foray into the core ethical considerations around AI in any field today: if we can do it, does it mean we should? Bezaitis and Robinson (2011) put it well:
“If the work we do makes a particular future more likely, that means directly affecting other folks’ choices. We have made a choice about what others ‘ought’ to do, which is exactly what we sign up for when we undertake to do ethnographic research in applied settings.”
Through the lens of these critical and ideological perspectives, our aim here is to develop simple and straightforward arguments that add nuance to questions of technology adoption that may seem like no-brainers outside of the research milieu and its close collaborators. We build on the wealth of scholarship in the EPIC library, examples from the broader literature around social science research with AI, and recent discussion of the impact of AI on memory and cognition to two arguments:
-
By relying solely on AI as a source of knowledge in early-stage innovation, we risk outcomes that are both narrow and shallow. This is particularly pronounced when the problem space we’re designing in isn’t well established and as such, little data is present in the training sets that make up AI models’ knowledge base, leading to shallow (or outright misleading) insights. Additionally, Large Language Models’ ability to set and maintain context, while a feature that makes them truly powerful language tools, can also limit how much we’re able to explore around and outside of that context, leading to narrow insights that do not encompass the world beyond the context we’ve set.
-
The speed of development of AI models is exponential and various applications of this technology in research are still emerging. Acknowledging a future where researchers do draw on these tools for insight and inspiration, we consider the impact of their utilization on the development of individual and team-level research skills and the internalization of learnings when making the turn to design.
In the first section, we examine the different types of data we encounter in early-stage innovation research and put synthetic data in the context of the larger dialectic between breadth and depth, building on Tricia Wang’s argument that “Big Data needs Thick Data” (Wang 2013). Next, we explore the fundamental principles of large language models’ inner workings and their embodiment into AI-generated users through the lens of research learning goals and desired output. We then expand on intelligence and the role of the researcher beyond just the desired outcome of research and make the case that in a design research context, the researcher is more than an ‘insights machine’ and helps develop a shared “team intelligence” that keeps stakeholder needs at the heart of design solutions in a way that exposure to insights alone fails to accomplish. We ask how that role as facilitator of team intelligence is affected with the introduction of simulated users.
In support of our argument, we offer some tangible examples from the literature and our own work that show how synthetic data and AI-generated users play out in real projects, offering both difficulties in leveraging them in service of human-centered design research and parts of our process where these technologies are finding use, with direct learnings and tales of caution on their implementation.[2]
Finally, we present a set of considerations that situate these tools as options within a broader set of research design choices and offer an outlook for the design research discipline as our encounters with artificial intelligence become increasingly frequent. Note that we do not propose avoiding AI-generated users entirely, and we offer productive uses for this kind of tool. Specifically, we suggest AI and AI-generated users, by drawing on LLMs’ ability to tap into broad collective intelligence (Levy 1999), may help design teams arrive at a stronger hypothesis set and refine their research questions before taking them into the field with human participants. We also highlight other valuable applications of synthetic data in research storytelling and data democratization—especially in cases where privacy of research participants is essential—and on promising applications for synthetic users in market research and other applications. This paper, however, is focused on exploratory design research for early-stage innovation and does not try to make broad claims about other subfields of applied social research. We welcome discussion on how these findings may apply or need refinement in a broader research context.
The Landscape of Big, Thick and Synthetic Data
In corporate settings, design, UX, and product research often must make the case for itself because it costs money, and its relationship to cash-generation is often indirect, even speculative. Although it is intuitive that spending on research and development leads to breakthroughs that will ultimately help firms innovate and win against the competition, research and development is often the first to go in difficult financial environments as companies focus on the balance sheet and cash-flow generating parts of the business (O’Connor 2019):
“Since the 1980s, U.S. companies have slashed spending on basic, exploratory science and engineering research, largely because they believed these investments wouldn’t be rewarded in the market. The benefits were too vague and not traceable to profits in the near term.”
There is a nostalgia for breakthroughs that came out of large research and discovery labs like Xerox PARC.[3] The funding of large open-ended research projects, however, is ever rarer and even labs like PARC, while successful in many regards, failed to capture much of the value they created (Viki 2017).
This is all to say that research often gets pinched, as is the case in the current moment. In recent years the cost of capital has increased, and large research teams (perhaps too large) put together over the pandemic have been culled back. Those that remain are being asked to do more with less (human capital, budget, time, etc.). Balance sheet thinking like this tends to trickle down into organizations focusing on quantitative results, and as researchers we begin to hear the same old refrains when doing qualitative work. “How much trust can we really put in that research?” “How much can we really learn from such a small sample size?”
The quant-qual pendulum is a cyclical trend that swings with economic hardship and advances in technology. Even though the EPIC community and our allies have made incredible strides highlighting the value of contextual inquiry, the temptation to revert to big sample sizes and small questions can be overwhelming due to its perceived rigor and relatively low risk to the balance sheet. To update the old joke, no one is ever fired for hiring McKinsey, you might say no one is ever fired for fielding a survey.
As Big Data took center stage over the last twenty years, it seemed we could suddenly engineer and systematize data collection in ways that directly talk to the business metrics of interest, decreasing or outright removing the need for the often messy, ambiguous and, quite frankly, tedious process of “talking to users.” Chief Finance Officers everywhere salivated, and researchers started wondering if we were “over” if we didn’t learn Python. But the big data approach has proven to have inherent flaws, as Wang (2013) points out succinctly: "What is measurable isn’t always what is valuable."
Drawing on research literature, journalists and her own expertise and experience, Wang cautions that the dilution of insight that happens when research is only conducted through the medium of numbers and “measurable” variables, calling it broad, but shallow data. “Thick” data, in contrast, is much narrower but digs deeper into the stories and contexts that give rise to specific “data points”. Ultimately, both are needed to form a complete and cohesive picture of a problem space: big data as a broad sweep of common, or average, patterns and thick data as a look into the social and contextual engines that ultimately give rise to those patterns. We learned to use big data for the “what” and contextual research for the “how” and “why”.
EPIC has long been the home for contextualizing new technologies and approaches within existing best practices in the applied social sciences, and In 2018, EPIC centered its conference around Evidence, hosting papers further exploring the potential for marrying big and thick data in productive, human-centered ways in response to the rise of Artificial Intelligence and LLMs as the next paradigm shift in “big data” (Arora et al. 2018; Yapchaian 2018; Smets and Lievens 2018).[4]
By the end of the 2010s, Artificial intelligence had seen several hype cycles and winters before finally getting the right set of ingredients to deliver on the transformative impact the field had been promising all along. But the exponential expansion of the AI applications of increasing complexity quickly outpaced the methods of big data collection and labeling that fed into their training sets. Issues like data privacy, incomplete or biased data and the cost of collecting ever bigger data sets that need to be meticulously labeled for training started imposing limits on the performance of AI algorithms—a battle that is currently being fought in capitals and courtrooms around the globe.
At the same time, advances in machine learning have allowed for more sophisticated data modeling, creating what is commonly known as synthetic data: artificially generated data that reproduces real world patterns as a way to address these deficiencies of big data and improve AI accuracy by generating “diverse and comprehensive datasets” (A. Kumar 2024).
Synthetic data is compelling and promising in cases where privacy is paramount, and speed and accessibility is key. One prime example of this is its use in health care through synthetic data sets generated either following well-researched and science-backed disease progression and treatment models (Walonoski et al. 2017) or to reproduce the statistical properties of real patient data sets without disclosing any of their identifying attributes (Henderson 2022). In IDEO’s 2021 work with a bio-tech pioneer we heard first-hand accounts of how synthetic data enabled them to plan and build a commercial facility at break-neck speeds, ultimately helping save countless lives through the delivery of a COVID vaccine.
Outside of a healthcare setting, we can point to other compelling uses of synthetic data as complementary or in place of biased real-world data sets by artificially boosting the frequency of certain underrepresented voices and perspectives. This is a good first step towards data equity, though to call the problem of missing and underrepresented data solved as a result would be a misstep (D’Ignazio and Klein 2023).[5]
Where synthetic data begins to show less promise is once we tie it into the bigger picture of information generation and dissemination: if now, the machines that are increasingly used in data processing are themselves trained on synthetic data or capable of generating it, the question of the validity of the output we get from machines becomes a chicken or the egg type of problem (Krenchel and Cury 2022):
“The coming avalanche of synthetic data not only blurs the lines further between ‘real’ and ‘artificial,’ it also promises to make it infinitely more difficult for the average data consumer to critically evaluate where the original data came from, how it was collected, and manipulated, and consequently to what extent we should trust it. How good was the model that built this synthetic data set? What can or can’t this data be meaningfully used for?”
Notwithstanding these shortcomings, quantitative and scientific research stand to benefit from both big data and synthetic data. One might expect design research, known for its use of thick contextual research, to be left alone. After all, the argument might go, surely early-stage Design innovation still needs the “thick” data to form a full picture, the deep human stories, challenges, pain points, needs, mindsets and motivations to glean deep insights from.
Yet this is where we’re seeing generative user simulations propose to offer efficient alternatives. Whether they’re truly capable of delivering the same output as in-context research with human participants depends on many factors that we’ll explore in the subsequent sections. To get there, we need to start by looking under the hood of Large Language Models and approaches to AI user simulations so that we understand what they have in common and how they differ from tested design research methodologies.
How Do Large Language Models and AI-generated Users Work Anyway?
LLMs and other modalities of Gen AI have been changing how design work gets done at the individual, team and organizations level. With speed and efficiency as a key value proposition and nourished by the hype cycle kickstarted with ChatGPT’s unprecedented success, they have seeped into designers’ workflows and processes seemingly overnight and brought on an avalanche of tools fighting for a slice of the pie. They have triggered a transformation in how we engage with AI through their unrivaled conversational abilities, which rely on two key components that set them apart from their predecessors: the attention mechanism (Vaswani et al. 2023) which primarily helps these models retain context across long conversations (as opposed to a few words or sentences); and additional learning through a human reinforcement learning layer, which tunes the models to respond in ways preferred by humans.
Underneath all of this lies a massive “cloud” of words, or in the machine world, embeddings. Embeddings are long arrays of numbers that represent a word in a mathematical space that spans thousands of dimensions. Through complex algorithms, including the two mentioned above, embeddings determine the probabilities that these words appear together in a sentence. For the sake of argument, let’s unpack the semantics associated with these tools.
“Large Language Models” is directly associated with the size of the training data and their output (large), their purpose (language) and what they are (models). Colloquially, we have come to refer to them as generative AI, a term that captures their difference from other machine learning models (capable of generating their own content, as opposed to relying on content as input to output some prediction). But, to quote Danillo Campos (2023), a term like “Pattern Synthesis Engines” feels more aligned with how they work:
“I’m more comfortable calling “AI” a “pattern synthesis engine” (PSE). You tell it the pattern you’re looking for, and then it disgorges something plausible synthesized from its vast set of training patterns.”
Although it’s highly unlikely we’ll collectively agree on a new term for LLMs after they’ve made a name for themselves as “AI,” it’s critical we keep the notion of “pattern synthesis engines trained on data collected and curated through human labor” in the back of our minds in the context of AI-generated users.
In a way, we can think of AI-generated users as a close cousin to the long-used strategy for representing target consumers in market research: personas. Personas represent a composite of data points that strives to communicate user needs, behaviors and ambitions and differentiate between groups in the target audience (Hall 2019), and their marketing strategy counterparts, segmentations.[6]
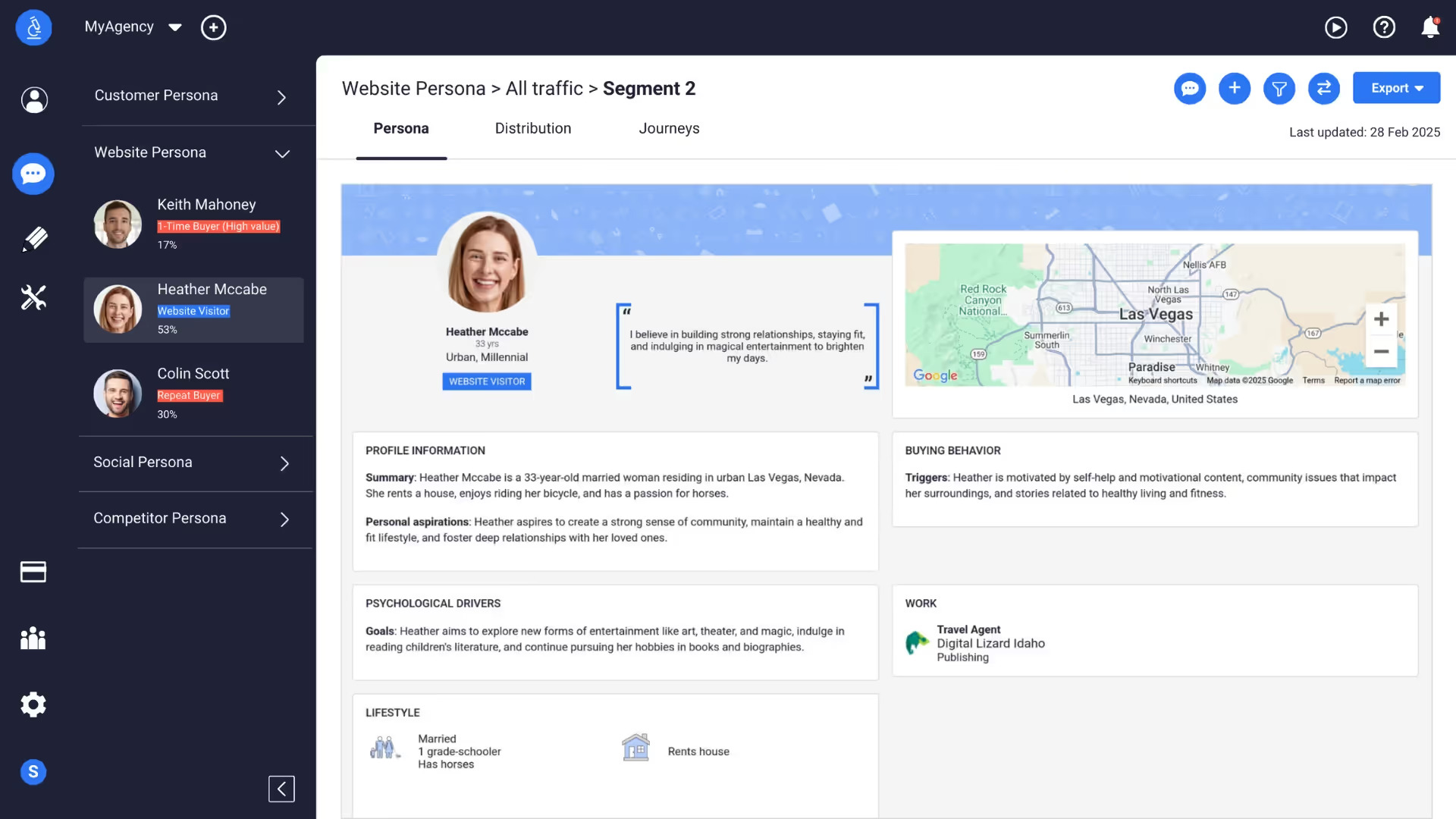
Personas and segmentation “typing tools” are typically among many potential research deliverables and can be based both on quantitative (for example, large scale market segmentation) and qualitative data (interviews, observation, immersion) methods. They can contain simple demographic data and a paragraph of user needs and behaviors or span detailed descriptions of frustrations and pain points with scenarios and supporting quotes. This style of persona generation has organically translated into how AI-generated users are broadly defined today (see Figure 1).
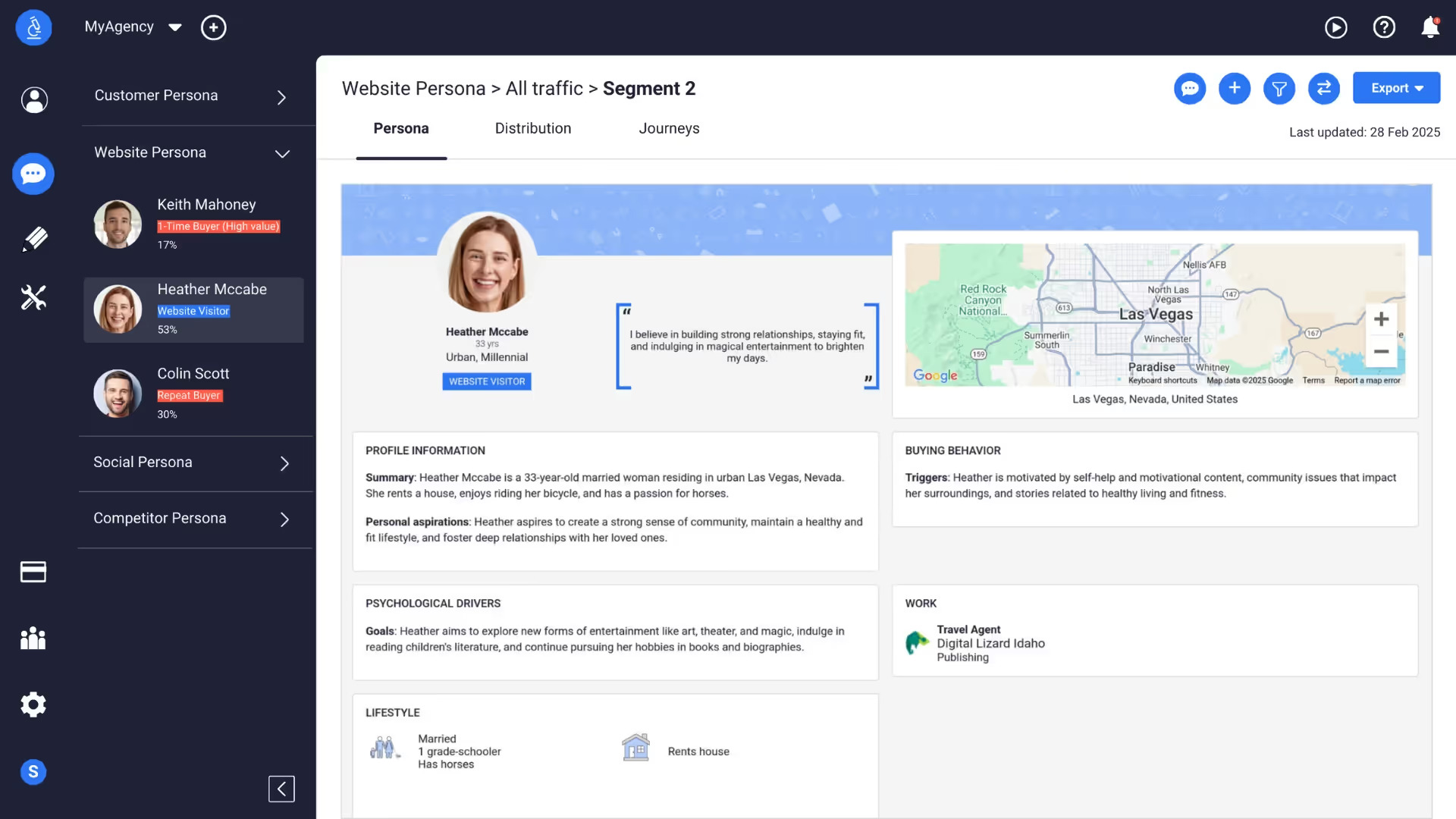
Before we examine AI-generated users through the prism of personas, it’s worth noting that there are other approaches to get to AI-generated users that don’t solely rely on an explicit persona prompt. They tend to be more involved as well as more expensive and time-consuming. For example, Park et al. (2024) showed that personas crafted based on 2-hour long generative AI interviews with 1000 real people (the transcripts of which were then included as memory for the agent simulating a real user), answered the General Social Survey 85% as accurately as participants replicating their own answers two weeks later. This type of AI generated user has been popularized as “digital twins,” or digital agents based on real people who can carry out tasks on behalf of the human, even answer survey or interview questions on their behalf.
Another approach that doesn’t include gathering data from real participants is through Generative Agents (Park et al. 2023), or autonomous software replicas of human behavior within a given socioeconomic system—a Gen AI-powered Sims, if you will. These agents, when equipped with methods of observation, planning, recall and reflection, show certain promise in simulating “believable” human behaviors. That said, each agent inside such a simulation is in a way an advanced persona, equipped with evolving memory, knowledge and capabilities, within an environment that’s defined by external rules and assumptions.
For simplicity’s sake, on average, we can think of an AI-generated user as an LLM injected with a specific persona. In most cases these are defined solely with a prompt, and in more advanced cases, based on real data collected from users, or even equipped with an environment, memory and ability to interact with other AI-generated users. If we think of the LLM as a pattern synthesis engine that draws on clouds of available data points most similar to the persona in the prompt we give it, what we get personified in an AI-generated user is a patchwork of voices and content from the internet, stitched together by complex algorithms and molded to behave in certain ways by human input.
What’s worth noting here is that all these mechanisms of persona generation, even the more advanced ones, are still far from representing true users due to their narrow, or incomplete, context. Personas are yet another layer of pattern synthesis, typically used to represent common mindsets, needs and behaviors of a certain group of people—patterns observed in research with users and framed through these fictional characters with the goal to have an easy reference point that would ideally keep a design team centered on user needs, and away from designing for their own biases and preconceptions, or an “average”, undetermined user.
As such, personas have seen the most use towards the end of research phases of product development, as a way to align key stakeholders around who their audience is, home in on specific marketing strategies, brand and communications tone of voice, or prioritization of specific features in UX design. They can be carried forward throughout the life cycle of a product, in development, deployment and testing and should evolve with time by keeping track of specific metrics that define the user needs and behaviors corresponding to each persona (Harley 2014). The Persona Lifecycle Framework (Adlin & Pruitt 2010) even describes personas as growing, reaching maturity and eventually retiring as they no longer represent a real user group due to shifting market or user mindsets. Throughout all these uses, personas are primarily a tool for storytelling, designed in a way that facilitates communication and alignment of teams that take on the work beyond research. As such, they have been a useful and popular tool in the design of many products, services and experiences.
Many researchers have also pointed out their limitations, especially when decision makers try to use qualitative personas as segmentations, and use segmentations to try to understand user needs (Hall 2019; Sauro 2018). The full extent of this discourse in the literature is out of the scope of this paper, but we’d like to point out limitations relevant here. While there are best practices for discovering and crafting personas and separately, market segments, there is an amount of discretion in how a researcher or team defines the specifics of it, which leaves room for them introducing their own biases and assumptions. Additionally, by focusing on the “average” or most common needs of a broad group runs the risk of oversimplification and overgeneralization, which inadvertently leads to leaving people out. This reduction of humans to a set of their needs, mindsets and behaviors disembodied from their full contextual life experience is especially at odds with practicing inclusive design, as it can further perpetuate the absence of voices not present in the data that informs these personas in the first place.
So how does this work in practice and what is it useful for? The answer isn’t straightforward, and as any application of AI in a real-world setting, it depends on the workflow and context it’s employed in.
We’ve already seen examples of where AI-generated users show promising outcomes. Argyle et al.'s (2022) AI-persona based simulation of the Rothschild et al. (2019) partisan pigeonhole experiment was capable of reproducing overall attitudes and perceptions in the broader US population based on where they stand on the political spectrum. The researchers, in this case, crafted the prompts for each persona they tested, but it’s also not surprising that the LLM alone could get close—after all, American bipartisan politics and opinions flood the internet across news, media, forums etc.—all places where the training data for LLMs was obtained from. Similarly, the Park et al. (2024) study used data from long AI-moderated interviews with 1000 people in a successful attempt to recreate the survey responses of those specific people. And agentic simulations, like the one undertaken by Almansoori, Kumar, and Cholakkal (2025) showed that equipped with the right knowledge database and real-time training processes, self-evolving AI-generated doctors were able to diagnose illnesses at levels similar to their human counterparts.
What all of these have in common is the pre-existence of large amounts of data, established patterns and knowledge needed to “power” the corresponding AI-generated personas. It’s worth noting that among these patterns are also a wide range of social and cognitive biases (Mei, Fereidooni, and Caliskan 2023; Döll, Döhring, and Müller 2024; Gallegos et al. 2024), which is hardly unexpected, considering the massive and messy datasets of human-generated content LLMs are trained on. Recent studies (Bai et al. 2024; Warr, Oster, and Isaac 2024) also demonstrate that implicit biases remain in explicitly unbiased LLMs, and in some cases, these biases are higher in more complex models (D. Kumar et al. 2024), highlighting the need for comprehensive bias evaluation benchmarks to ensure the outputs we get from LLMs are aligned with fair and responsible decision-making. Ensuring LLMs are bias-free directly impacts early-stage innovation within the context of responsible and inclusive design. If, on the other hand, our goal is to work “with” these biases as a way to inform human patterns of thinking and behavior, we have no direct way to probe whether the kinds of patterns we’re looking to uncover are present and prominent in the data that powers LLMs. A stark example of this is a German study akin to the partisan pigeonhole experiment, in which AI users failed to accurately reproduce the patterns present in the German voter population (von der Heyde, Haensch, and Wenz 2024).
One compelling use case of AI-generated users in today’s landscape is in automating website flow tests: once the user journeys and flows are established, websites simulate users in different digital environments (operating systems, mobile vs web etc.) and continuously ensure the user flows don’t break. We believe this may also be a good opportunity space for deploying “digital twins”. Interaction data on websites is already being collected, so what if people could opt into it being continuously collected and used to train their digital twin, which can then take part in user testing for new features—and ideally have the user compensated for it, without them needing to do tedious surveys and tests.
Designers and researchers are often working in problem spaces that cannot be understood purely through social experiments that rely on large data sets. At IDEO, our use of AI and AI-generated users often happens at the very start of a new challenge: understanding the broad market landscape, compiling and synthesizing existing relevant studies, and when the circumstances call for it, even crafting AI personas to chat with as a prototype for user interviews. We do this to help our teams challenge early assumptions and broaden the aperture for both inquiry and design or simply get comfortable with the process before going in the field.
For example, a team working on a short sprint with a nonprofit that serves the aging population in the US and their caregivers, built three different AI personas of informal caretakers as a way to both demonstrate to our client the capabilities of the technology and as a first step in training the clients in conducting interviews, which they were to carry on internally in their organization. This was complemented with having them observe IDEO researchers conduct interviews with real stakeholders, and vice-versa, researchers observing the clients conducting in-person interviews and offering feedback. AI-generated users in this case were a tool to get novice researchers comfortable with conducting interviews on their specific topic of interest quickly. But the output from these AI users wasn’t used to inform ideas and concepts. If anything, the consensus of the team is that the users were quite generic and didn’t help them learn anything new, so while useful as a process demo tool, the output from AI-generated users in this case proved to be somewhat circular, speaking back to the team their own assumptions.
Where we’ve really seen synthetic data and simulated users fall short is in design innovation outside of purely digital spaces, or digital spaces where established protocols are non-existent or performing poorly. A standout example of this in the literature is Salehi’s (2023) attempt to reproduce a study she co-authored (Robertson, Nguyen, and Salehi 2022) using one of the commercially available AI-generated user platforms. The original study examined underserved families navigating enrollment in the school system and how online resources could help them in that process. This study, which involved interviews with 10 underserved families in the Oakland school system and 4 individuals with experience helping such families, was published in a paper titled “Not Another School Resource Map: Meeting Underserved Families’ Information Needs Requires Trusting Relationships and Personalized Care.” Initially framed as a study about online resources, by interacting with the impacted individuals, the researchers quickly realized the solution wasn’t making online resources better, but moving away from online resources altogether. Reproducing this study with AI-generated personas didn’t even come close to this outcome, with AI users sticking closely to the prompt of giving feedback on existing online resources instead of broadening the overall real-world context in which families facing these challenges exist.
Similarly, an IDEO team working on healthcare solutions for rural and remote communities in the US employed AI in various contexts, including “interviewing” AI-generated users (Jambo et al. 2023). In our case, we found the AI users stuck too close to our own prompts and failed to bring up factual and relevant information on how the healthcare system in the US works. For example, one AI user, which we designed as a patient with limited English language proficiency, surfaced many challenges around language and struggles with understanding their doctors’ notes, saying they often have to use Google to translate them with their wife at home.
A quick conversation with a healthcare practitioner revealed that US hospitals are required by law to provide interpreters to patients with limited English proficiency. If we hadn’t been thoughtful and broad in our research practices and only used the feedback from AI users that we infused with our own lack of knowledge and biases, we could’ve gone down a futile design rabbit hole trying to solve a non-existent challenge. It’s worth noting that outside of this example, AI proved useful for desk research on the common challenges faced across rural communities in the US and the US healthcare system. But when it came to uncovering specifics and nuances within the space, and in particular, ideating and validating potential solutions, the AI approaches weren’t up to par with human experts and people with relevant lived experiences.
This example shows how in early-stage innovation we use expert participants to respond to our questions, but also to point us to deeper questions we may ask or show us how the questions we’re asking are not the right ones. This is, of course, at the heart of qualitative methodology where we ask open-ended questions designed to help us update our learning goals as we go with the aim of discovering new information. The researcher is the learner, benefitting from the participants’ expert knowledge. Turning to agentic simulations at this stage risks flipping that equation.
In open-ended interviews, we follow the lead of participants, inviting them to take us on their journey, even when—or especially when—it seems to deviate from what we thought we were going to talk about. Looking at something from research participants’ points of view leads to things we never would have learned otherwise, and creates sparks of insight that help us shift priorities or radically reimagine the problem we’re trying to solve, as well as potential business outcomes. These interviews, when carried out in specific contexts (like a people’s home, workplace, gym, etc.) offer additional contextual clues that can drive the conversation. People’s artifacts, photos, prized possessions, accidental intrusions from family members—and a host of other things—can dramatically alter the course of a research experience and lead to new insights.
The design logic behind many Gen AI tools can sometimes be at odds with what researchers consider effective practice:
-
People pleasers: They are designed and trained to please you and be helpful. Sometimes participants try too hard to be helpful as well, but researchers are trained to sense this and dig further. There’s nowhere to dig further with a synthetic user.
-
Emotionless entities: Contemporary LLMs lack authentic emotion. They don’t leave the markers and cues that participants often drop to signal there might be more to learn. And if you want a more emotional response, then it’s up to you as a researcher to prompt it—which can add researcher bias that doesn’t reflect how a typical user would feel.
-
A shallow context pool: LLMs must be fed the right context. They can’t say unexpected things beyond what you’re already asking about. Meanwhile, researchers are only able to define what’s relevant as the process unfolds.
-
Forced assumptions: Actually, writing a prompt that gets you meaningful answers requires you to make many assumptions about what you might learn.
All of this brings us back to the big, synthetic and thick data discussion. We’ve already seen how big data, alongside synthetic data, is most appropriate to use when we need a broad sweep of general patterns in needs, attitudes and behaviors. AI-generated users are, on a first glance, ways to dig into that big data and surface specific needs, attitudes and behaviors. But AI models, at their core, are big data models, not thick data models. So, AI-generated users are, at best, a mechanism to further filter down the “clouds of words” that are relevant to our inquiry, but the output is still content that has been averaged out and diluted through the mechanisms that make LLMs (or pattern synthesis engines!) work. As such, we should be cautious when claiming to use them “in place” of user research—they are not a one-to-one representation of users, especially when we’re after thick data.
Here’s a final example that illustrates this: one of the authors of this paper made a ChatGPT persona of their partner, with consent, and interviewed them side by side. The persona prompt contained the typical ingredients: age, gender, place of birth and residence, interests, personality traits, some needs and behaviors. This GPT persona correctly guessed their favorite video game and their top 2 (but not top 3!) travel destinations, without them being explicitly stated in the persona prompt. This is very much the big data benefit of AI-generated personas—the likelihood of anyone at that age with that background and characteristics to have Zelda as their favorite game and want to travel to Japan is pretty high, because certain video games and adjacent interests are experiences that were shared by many growing up during the late 90s and early 2000s. Where this AI persona failed though, is in the thick data type questions. While the AI persona answered Zelda is their favorite game because it’s “an imaginative, open world that you can explore”, the human it was based on said in response to the same question “because it literally saved my life when I was a lost teenager”. If we were, for example, designing a new video game, the AI user’s response may speak to how we design the world of our game. But the actual user’s answer opens a whole new realm of questions around people’s emotional attachment to games and the role they play in their lives, even across different life stages.
Finally, let’s assume for the sake of argument that we know we can accomplish a truly faithful representation of a user with AI.[7] In the next section we argue that even in this case, where the “time to insights” might be instantaneous and the insights themselves of quality on par with human-derived ones, another critical factor to consider is the desired outcome of the research process as a whole. Is it just an insights report that is to be discussed once and never looked at again, or do learnings need to be integrated in a way that builds the individual and team intelligence essential for intuitive and rapid innovation?
Cognitive Offloading, Team Intelligence, and Researcher Expertise
Thick description is not just about the collection of data, but the deriving of an interpretation from the data that only is possible through the process of writing fieldnotes (Geertz 1973). This interpretive layer is what separates an observation from an insight (Cury 2015). The researcher isn’t just a collector of evidence, but a facilitator of understanding. Having discussed the utility of data captured through synthetic users in early-stage innovation in the previous sections, we now want to turn our attention less to intelligence as the end product in the form of insights, but rather to intelligence formed as a part of the design process in the form of team intelligence and what cross-disciplinary collaboration can look like when fieldwork is automated.
In the field of design, research is always in service of producing the future (Bezaitis and Robinson 2011), and research findings are rarely the team’s primary output. Instead, insights and learnings about the users and markets are developed to generate and refine design products or concepts — real things that can live somewhere out in the world. Creating insights to drive design outcomes effectively relies on continuous cross-disciplinary collaboration. Ideally where there is no real “hand-off moment” between design and research, though this isn’t always possible given organizational constraints.
One benefit this kind of collaboration affords teams is the ability to design at speed—by being a part of the research, designers can more quickly apply learnings to the design. However, a focus on speed alone suggests a model where collaboration serves only to minimize inefficiencies in hand-off moments between the production of “insights” and “design concepts.” If speed is the factor to solve for, it would seem that integrating artificial intelligence into research processes is a great solution whether it’s learning from synthetic users, sensemaking or storytelling.
Indeed, there is the notion that by integrating time-saving tools into the workstream, and out-sourcing the tedious bits, we can actually elevate the role of the researcher from menial tasks to “strategic,” “higher-order,” activities to be completed referencing the outputs from AI supported workstreams. In this view the researcher becomes less of the ‘do-er’ of research and more of a research manager with agentic AI functioning as an eager unpaid intern (Mollick 2023; Whitfield 2024).
Exploratory research requires more than “speed to insight,” and the best outcomes rely on design and stakeholder deeply understanding the problem space and building empathy for the users (Cury, 2015; Roberts, 2015; Cardona, Saldarriaga, Estupiñan, and Gamboa 2018). We argue that this team intelligence is built up through the hard work of doing fieldwork and yields dividends (in quality and speed) during later stages of the work as the team is able to connect-the-dots more easily and evolve concepts as new information becomes available.
Friction, usually derided as an obstacle, when encountered during the design research process, can be productive in fostering innovation, collaboration and organizational growth (Anderson and Cury 2023), and that we should be uneasy about technologies promising to make things cheap, fast, and good. This notion of helpful friction has an affinity with findings from the field of neuroscience and learning theory (Oakley et al. 2025). Oakley et. al. show how cognitive offloading, the reliance of learners on external aids e.g. calculators for arithmetic, AI for writing, etc.), can prevent deep understanding and slow the development of mastery of a skill —both of which, when applied to design research have significant implications in the context of early-stage innovation.
By looking at memory formation, consolidation and retrieval, the authors show that cognitive offloading interrupts the internalization of information, “leaving us with superficial schemata—weak mental frameworks that can’t adequately support critical thinking or creative problem-solving.” The authors make an argument in favor of friction in the development of intelligence, placing an emphasis on tedious memorization and practice—challenging a popular belief that pedagogy had evolved past such a “mage on the stage” approach to learning instead focusing on educators as “guides on the side” to make progress in difficult subjects.
"A student remembering that they can ask an AI to explain photosynthesis doesn’t activate the same neural networks as actually remembering how plants convert sunlight into energy…with repeated use and retrieval practice, initially consciously recalled information can become more automatic and intuitive. This often involves a transition between the brain’s two memory systems [declarative and procedural] and is crucial for developing expertise.
When one uses their brain to retrieve information, that knowledge, over time, moves from deliberate ‘declarative memory’ to automatic ‘procedural memory.’ This transition in memory offers several advantages to the learner, a role, for the purposes of this paper, we are inviting the researcher to inhabit:
-
Retrieve information more quickly
-
Integrate new information more effectively
-
Breaking out from habitual thinking by noticing connection between ideas
-
Notice errors or surprising outcomes based on internal ‘prediction’
Proponents of the “unpaid intern” approach to integrating AI into workflows suggest that checking the AI’s work is crucial. But what does that mean for a research team that has not built the contextual intelligence (Khanna 2014; Spillers 2024) necessary to notice something surprising or dubious?[8]
Ironically, when we short-circuit the development of schemata by relying on digital tools, or mental models via cognitive off-loading, the learner is less equipped to engage in the higher-order activities that proponents of “out-sourcing” typically promise. The seniority and previous experience thus become crucial to how one engages with AI tools in this, or any, context. Junior researchers share the same challenges with junior writers, programmers, artists and many other disciplines: with AI tools being readily able to do their jobs with (or for, or instead of) them, they are faced with fewer opportunities to build up the muscles needed for more senior roles. Not having the opportunity to acquire the level of knowledge and experience of their senior colleges also makes this group less equipped to check and challenge AI outputs in their work.
“Without practice, the basal ganglia circuits don’t get the training trials needed to optimize the skill. The result is a learner who remains reliant on conscious, declarative processing (or worse, on the tool itself) for tasks that could have become automatic. This not only makes the tasks slower; it also chokes off higher-order cognition, because the person’s working memory is consumed by basics.”
Further, struggling with recall and the application of information stored in memory can lead to stronger mental schemata and the elusive “aha!” moment that is so sought after in early-stage innovation work.
“Often, creative breakthroughs occur precisely after we feel most stuck or confused. At these moments, learners are primed to reorganize their understanding, producing the well-known ‘Aha!’ experience.” Indeed, cognitive scientists refer to challenges that feel difficult in the moment but facilitate deeper, lasting understanding as “desirable difficulties”(Bjork, Bjork, et al. 2011).
Oakley et al.'s findings are consistent with other recent headline-making research from Microsoft in collaboration with CMU that found that confidence in AI generated results contributed to lower critical thinking (H.-P. Lee et al. 2025). The MIT Media Lab too has found effects among LLM users on cognitive activity, as well as perceived ownership and ability to accurately quote their own work (Kosmyna et al. 2025) with participants who used LLMs to write essays struggling with recalling parts of the essays minutes after ‘writing’ them.
By looking at how we design for learning with AI, we can locate clues for applying similar principles to our own learning process as researchers. At IDEO we have prototyped what AI powered learning tools could look like that do not promote cognitive offloading. For instance, our work with Ethiqly, an edtech startup providing writing help to students and teachers, leveraged the multimodal aspects of AI. In our research with students, we found that “staring at the blank page” was the biggest hurdle to getting started with writing assignments. So, we built a tool that lets students talk through their thoughts around the topic, completely loose and unstructured, then transcribes them and sends the transcription to ChatGPT, which returns a list of keywords. The students can then organize the keywords into sections and start writing out each section based on a draft derived purely from their thoughts, but with the kind of assistance AI is best posed to offer a learner: structure and organization vs. providing an answer.
In a different project IDEO investigated the process by which sub-contractors learn the proper way to install siding material on residential properties. There was a lengthy book available, full of technical language that could ostensibly ‘answer’ any question an installer might have. In our qualitative research we learned that there are highly contextual problems that aren’t found in the book, and moreover “you can’t fucking throw a book at 'em,” as one participant put it.
Contractors are not much different from design teams in this regard. Design Research needs similar AI tools that allow us to learn as well as acquire knowledge, a question that the EPIC community has been grappling with (EPIC People, Oudu 2024). Static insights alone aren’t enough to build the capability to flexibly deploy them with skill, and a written insights “deck” isn’t an artifact that a designer will return to for cultural and practical reasons.[9] While this finding had clear implications for the design team prompting a good “how might we” question about designing for learning, we can pose a similar question for our design process: how might we leverage AI agents and synthetic users to add helpful friction that supports learning and expertise instead of taking it away?
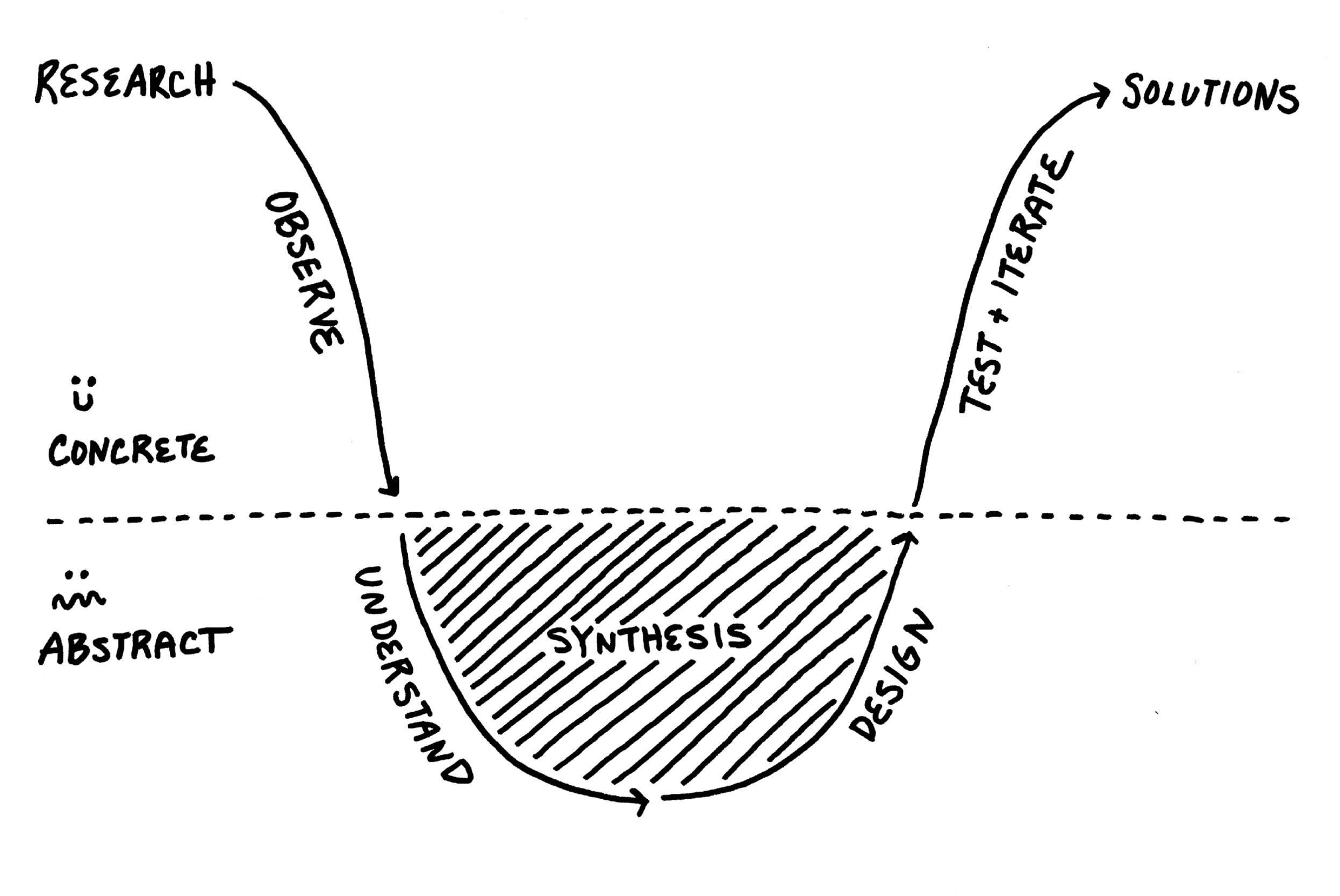
At IDEO we have a name for this friction-full “messy middle” of the learning process that ultimately gets results: the anxiety gap. To prepare our clients (and new hires) for the emotional rollercoaster that research can feel like, we often use the diagram shown in Figure 2. We show it not to point out the inefficiencies in our process but to demonstrate the necessary emotional low points in the learning process that are part and parcel to the hard work of fieldwork.
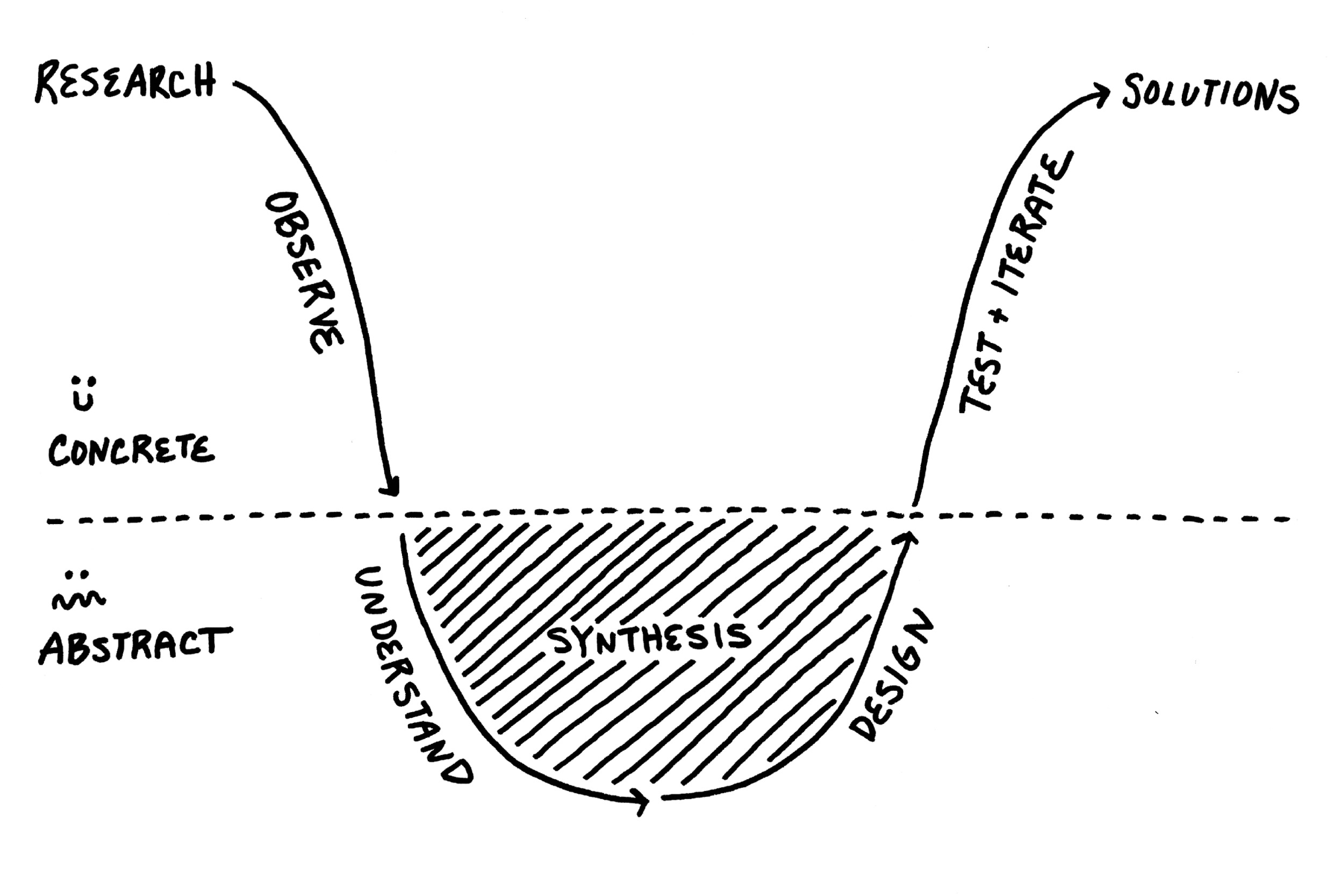
In Oakley et. al.'s account or developing deep understanding, researchers may recognize as best practices for fieldwork and synthesis:
-
Exposure: Having the full design team in the field to learn first-hand from participants.
-
Immediate Reflection: After completing an interview, we download the information as a team providing space for reflection that regiments information in memory.
-
Repetition: We take photos of our participants and their context and plaster our project spaces with them to further engrain the memory of the fieldwork. We share data early and often with clients.
-
Analogy: We build mental models that connect the dots and function as schemata externalized, which we share with our clients to help build a shared intuition for the learnings from the field.
We do these things to turn contextual intelligence gained through empirical, exploratory research with real people into a shared cross-disciplinary team intelligence in which learnings from research are internalized and deployed during subsequent (more concrete and less exploratory) iterations of design and research.
Sometimes stakeholders who share this team intelligence cannot actually be there for these steps. For instance, clients may be invited to be a part of research so they can share the team intelligence generated through fieldwork and sensemaking, but it’s not always possible. To account for this, the design team might create immersive workshops with the clients to bring them into the research process. This can look like a gallery walk, a short video, a podcast, or even sketch comedy. By doing this, one captures the audience’s attention and to help them build empathy that supports deeper understanding of the insights being shared. In a setting where insights are generated without fieldwork, the researcher should consider how to create more immersive learning experiences for the design team to build intuition for the findings or distribute research tasks across the team so that the designer is responsible for sharing findings in a way that moves learnings from declarative to procedural memory (i.e., not relying on AI to do it).
With all of this in mind, we can begin to think about the role of the researcher on the team to facilitate this shift from contextual intelligence to team intelligence, a job that at IDEO is characterized as “owning the research.” This amounts to setting the conditions for exposure to contextual intelligence most helpful to the design brief and the facilitation of processes aimed at the development of a shared team intelligence.
This is good news for design researchers, since both functions exceed the limited role of the researcher as “findings producer” that AI generated panels aim to disrupt. If we can’t create team intelligence through participation in fieldwork, at least we can build it in other ways. However, it is also the case that the researcher needs to be the expert in content and process on the team to maintain a rigorous process and to elevate the “voice of the user” to ensure team intelligence stays grounded in data (as opposed to vibes).
If there is an evolution in the role of the design researcher at-hand, it is less about moving from being the producer of insights to the strategic manager of insights, and more about continuing to facilitate highly contextual and actionable team intelligence with fewer resources to play with.
This shift puts a greater emphasis on the expertise of the design researcher. For those of us who have been doing early-stage innovation research for a while, we can claim to have some degree of expertise when it comes to craft. And while there can be an advantage to having a ‘beginner’s mindset’ in terms of being open-minded to new ideas, our array of past experiences provide a war chest of analogous findings to spring off-of, allowing us to more easily pick up the pace when facilitating new learnings for our teams, and spot issues in the results from more automated research workflows.
Integrating AI tools may be a riskier transition for junior researchers who do not benefit from the same number of “reps” as more seasoned researchers. And if we fail to support those junior researchers with timelines, methods, and tasks that develop craft mastery, and instead encourage them to rely on digital aids, there is a real risk of failing to develop the next generation of research expertise within our organizations.
Applying the same logic, there is a risk of failing to develop skills around new AI tools. In order to recognize “what good looks like” in leveraging AI tools for research in service of design, a researcher needs exposure, reflection, repetition and analogy. In other words: practice. It is the challenge for the organization to offer opportunities for both and be flexible but rigorous with the experimentation with tools like simulated users on projects that may have real-world impact.
To summarize, when you let technology do the thinking you put a ceiling on how the team will be able to engage with the material and any potential creative leaps. For Oakley et al. this helps to explain the so-called “Flynn Effect”, the trend of lower IQ scores in developed countries in the last 50 years. For others at MIT and CMU there is a risk to developing critical thinking skills.
In early-stage innovation where research is in service of design, even if the insights returned through a synthetic or automated process were accurate and useful, the risks of cognitive off-loading on the efficacy of synthesis and prototyping are more far-reaching:
-
Failure to spot dodgy or surprising data
-
Failure to translate contextual intelligence into team intelligence
-
Failure to think creatively (and strategically if you like) about research implications
-
Failure to develop research expertise
How might we instead use AI users to build team intelligence and make researchers more prepared to use time with participants in-context?
Considerations for AI in Early-Stage Innovation
The value proposition for agentic simulations is that you can use them when you don’t have time, budget, or personnel for the real thing. Overall, we don’t think learning from real people in the real world should have to be a luxury, but even within the constraints of the contemporary business landscape there are other ways to do good research that don’t require agentic simulations.[10].
We believe a more interesting question is what other methodological affordances do these uncanny digital doubles provide? Like any other choice in research design, which approach you select should depend on other drivers that determine the kind of data you want to leverage, drivers such as the research questions and the design challenge. Below we offer a few frameworks for leveraging synthetic user data (or not).
Exploratory Research
Well Established and Niche Problem Spaces
Design research is done in service of design, and its primary purpose is to inspire design teams in their ideation by highlighting the lived experience of people who care deeply about the problem you are designing for.
For exploring established problem spaces, in which data are available, there is utility for synthetic users in applied research as a way of plumbing the universe of existing knowledge on the topic, which can take several different forms. We can use it in combination with AI-augmented secondary research as a storytelling and research democratization tool: find target groups from existing data, craft AI-generated users from the data and share back with the team as a way to explore the problem space in a more conversational and interactive way. An alternative to this method that doesn’t rely on AI-generated users but may be equally, or in some cases, more effective, is what we call social listening—aggregating available public conversations online that are related to our problem space to explore in more depth common themes, supported by direct quotes from the users, in their own tone and voice.
In niche problem spaces, or in arenas with especially complex stakeholders sets, in which the amount of existing, or historical data approaches zero, synthetic users will have less utility and higher degrees of risk as the simulated agent makes logical leaps to address the questions being prompted. In this case, AI may be helpful in understanding the broader landscape around the problem space, but not necessarily your niche problem space.
The same is true for recruiting profiles. In recent years, our field has evolved in the popularization of research methods that bring our participant population into the research process more, such as co-design, embedded participant experts, and community design research, in which the participant population does the research themselves. We apply these approaches for a variety of reasons—ethical, political, and practical. AI generated simulations represent an abrupt departure from this trend, isolating the design team from those they will be designing for. If your recruiting profile is niche or involves people from a protected category (e.g. people with disabilities), the dangerous and unethical side of AI generated doppelgangers is thrown into stark relief, and how a new tool that seems to be future-facing risks throwing an industry back in time.
Building Team Intelligence and Craft Mastery
In a recent blog post, Alex Martisinovich, a software engineer, describes AI etiquette, and argues it is the height of rudeness of offering up unfiltered GPT ‘slop’ to a colleague as an answer (Martsinovich 2025). To be clear, we are not suggesting that the products on the market today are ‘slop’ or akin to outputs you would get from a simple prompt with an untrained GPT. Rather, we bring this up because it highlights that while something can be useful in a process, that isn’t worth sharing as the final output with clients, external or internal, whose attention is limited and may be prone to anchoring on certain low-confidence-level findings. At IDEO, we bring clients into the work early and often, and when we offer early hypotheses or signals from research (which we often do) we add some very big asterisks to make it clear that it is WIP.
At this stage we think it is disingenuous and harmful to pass off a synthetic “in-depth interview” as research, but at the same time, we do believe that artificial intelligence can be a helpful tool in the research process for building team intelligence and craft mastery.
Already 43% of American workers have used AI at work and 77% of UX Researchers are using artificial intelligence in their workflow, primarily informally, and leveraging out of the box GPT to experiment and solve their own problems — suggesting an opportunity to form best principles for doing so in a productive way (User Interviews, 2024).
We believe there is use in simulated users as a way to build strength and ‘pressure test’ research protocols before going live. Although we do design reviews on research protocols, having additional feedback on the discussion guide would be helpful to"
-
Generate new learning goals as a team
-
Build design research skills on the team
-
Practice specific discussion guides to test for clarity ahead of fieldwork
-
Identify unintended consequences of a discussion guide ahead of fieldwork
By repeating the research process, the researcher will be nimbler in the field and make the most of their time with live participants. Building on Yatani, Sramek, and Yang (2024)’s set of extraheric[11] AI interactions that support critical thinking, we can imagine a layer that offers scaffolding to offer nudges, questions, and suggestions to the researcher as they run through the simulated interview encouraging reflexive thought and problem solving.
Though adding another step to the research process, isn’t exactly what the developers of simulated user panels had in mind, it’s using the data for a purpose, not a playtest.
Building Confidence
Attitudinal and Behavioral Data
There are types of information that are difficult to elicit with a high degree of confidence from traditional, ethnographic-inspired design research methods. As any social scientist will tell you there can be a big difference between what someone says and they actually do. This is true for asking someone about what they’ve done in the past because often we aren’t very good at remembering, and it is certainly true when you ask someone to anticipate what they will do in the future because we are so bad at predicting our own behavior — or admitting it to a nice researcher in a recorded interview.
In this light, there is an irony to how well-established certain metrics are in market research that rely on self-reported data to indicate future behavior (e.g. the NPS score) — but there is a real need to build educated guesses around future behavior.
One way to address this “say-do gap,” is using design as a method of research, such as creating prototypes in the form of sacrificial concepts, immersive experiences, and even play-acting to ask questions in a different way that help participants imagine future states to provide helpful feedback in the development of a product. But these methods are not the best for understanding things like willingness to pay and rigorous testing of tradeoffs at point of purchase. We tend to rely on traditional quantitative methods like conjoint analysis and MaxDeff scaling to build confidence around concepts once they are at a level of fidelity appropriate for that kind of testing.
There is good reason to believe that AI generated panels would be helpful for this kind of testing geared towards more granular learning goals, especially given the rise of artificial intelligence bots within survey panels we might normally turn to (Liem, 2025). Indeed, we have even noticed within our design research operations team, the increase in participants signing up for research who use AI to impersonate the target participant profile. With synthetic panels you are leveraging artificial intelligence with intent instead of by accident.
Brand, Israeli and Ngwe (2023) have shown that synthetic user panels are comparable to their human counterparts in forced choice exercises in which participants weigh trade-offs between prices and product features. However, they show how when specific qualities were added to the synthetic participant profile, responses showed exaggerated effects not seen in the human data.
It’s worth noting that these forced choice methods typically come later in the testing and validation phase of early-stage innovation, and In cases like this the best solution may be a blend of methods and triangulation of results, ideally involving rounds of in-context testing to further refine the synthetic panel model. We would love to see synthetic panel products really aimed at leveraging in-context research vs. acting as a substitute for it since LLMs can be good at nailing exploration of data they are trained on for prescribed tasks. We are all for making your own data work for you.
For instance, there may be value in using simulated panels as a start-up in the pre-funding or ‘bootstrapping’ phase, in order to demonstrate that there could be a there, there. This kind of evidence is used less for explicit design outcomes and more to show confidence in a potential product-market fit. At this phase of entrepreneurship, the business is built on assumptions, and the output of a synthetic panel, like any other risky assumption would need to be further de-risked.
The Continued Promise of Human-First Research
In this paper, we’ve addressed the emerging trend of using simulated research participants to drive design outcomes in the early stage of products and services development. We’ve shown how in early-stage innovation there are numerous pitfalls to relying on simulated data versus going out and learning from people whose stories don’t yet exist in any dataset out there.
Hoy, Stripe and Van Hofwegen (2024) showed that different kinds of expertise are valued in different contexts using the example of a traveler seeking help on how to plan a Paris vacation. The traveler valued artificial intelligence for some aspects of the trip, and desired expertise that came from personal experience when it came to specific trip recommendations that wouldn’t be found in the aggregate. As design researchers, we hold an analogous point of view that data outside of the existing dataset will lead to better breakthrough design solutions.
First-hand learnings from these activated, extreme or edge users (whatever you like to call them) has been key to the methodology for human-centered design deployed by IDEO and other firms like it that are tasked with creating new solutions to complex problems in which the problem to design for is unclear or ambiguous. We stand by that approach even as AI tools have made other aspects of the “research stack” more automated. Drawing on neuroscience and recent findings related to the impact of using LLM in knowledge work, we’ve argued that beyond missing key insights, relying on synthetic panels and LLM driven sensemaking tools can diminish the potential of the data’s utilization on design teams and hurt the development of researchers and designers within our organizations.
It is foolish, however, to think that artificial intelligence will go away or fail to touch early-stage innovation work. Why would it, and why should it? We believe there can be a place for it and have attempted to map out the parameters of that space. Indeed, greater than the risk of AI being diminished in the early-stage innovation space, is the risk that AI will become the norm. According to Andreesen Horowitz, a reckoning is coming in which the next wave of AI native and Generative agent tools will eclipse traditional “human-led” research. Along with ‘business analyst’ and ‘software developer,’ ‘market research’ roles are in steepest decline among white collar jobs in terms of new postings (Cohen and Amble 2025)
It isn’t difficult to imagine a world in which this prediction comes to fruition, in which agentic moderators interviewing agentic participants is the norm. It’s not unrealistic to imagine “user research” will be completely automated, from user panels, to moderation, to synthesis, to storytelling, and that what we encounter as consumers will be driven by ideas spawned by LLMs and tested in synthetic markets. Pushing this logic to the extreme, one wonders what decision making or human intelligence is needed in business at all!
When put this way, the threat to our industry as researchers and professionals committed to human centered design is an existential one. However, after the big data revolution, not all research has become quantitative, and there are still jobs for those of us who specialize in “thick data”—though those jobs have changed in response to the availability of big data. The question therefore is not whether or not artificial intelligence has a role in shaping team intelligence (that will happen, as AI improves in its ability to offer source material as inspiration), but rather what questions we believe warrant the investment in contextual intelligence, how we describe the value of it, and how we deliver on the value of it. Through this lens, with the groundswell of synthetic data, we believe human-first empirical evidence becomes further differentiated. In a world in which answers are easy to find, empirical research that surprises and is at tension with the known universe of data can become an advantage.
The immediate future of design research will be one where “human-led” gains steam as a reaction to “AI-driven” and researchers and organizations will have to weigh their options and evidence (or search their feelings as the case may be) and pick a side. Ultimately there will be a synthesis in which “human-led” contextual, qualitative research adapts to an AI-driven paradigm shift in how businesses and markets think about data, and simulated user panels in their best form will improve to serve the areas of experimentation and decision making in which they are strongest, and in their worst will serve as an illusion of understanding at a low upfront cost.
Research Ethics
Unless stated otherwise, all primary research we referenced in this paper was conducted as part of IDEO project work with clients. All methods are reviewed by senior leaders as well as designed in collaboration with our clients. We adhere to a rigorous set of ethical guidelines, including an informed consent process, adherence to strict HIPPA and GDPR regulations, etc. Regulations and legal considerations aside, our design research process centers the voices and practices of our participants and their agency in how they are represented in our work. We have made our ethical guidelines public in the Little Book of Design Research Ethics.[12]
Recognizing that this paper is mainly oriented towards an audience of researchers, we suspect that our reader will have strong opinions about the idea of a fully automated research function and emotions ranging from excitement to the existential professional despair of being tossed into the dustbin of history.
The authors of this paper all work at IDEO, a design agency, working with both quantitative and qualitative data in different ways as a result of our training as design researchers and professional experience in information sciences, data science, physics, anthropology and consumer insights. Those perspectives are reflected in the sections that follow.
Indeed the origin of our field and this very community emerged from the intersection of social sciences and engineering (Chris 2015).
At IDEO we have long championed in-context research and getting inspired by human stories at the edge of the target user population to drive responsible innovation. At the same time, we have always been quick to experiment and aren’t particularly picky about the tools we choose to incorporate into our design practice — alignment on ethics, purpose and a collaborative way of working has always been more important than one approach or another. Realizing the impact of Big Data and what we gain by being able to learn from and “play” with it, in 2016 IDEO acquired Data Scope (a human-centered data science company) and integrated data science into our research and prototyping toolkit. In 2018 and 2019 IDEO shared examples of that integration at this conference with presentations from Ovetta Sampson and Marta Cuciurean-Zapan respectively.
A non- or less biased synthetic data set begs the question: how did the designers of that set ensure their own biases, or the biases of whatever they were basing the bias corrections on didn’t seep into their assumptions? This is a much broader discussion to be had that is out of scope for this paper.
We recommend caution with qualitative personas as marketing tools. We have observed that they can lead to much confusion, inefficient marketing strategy, and eventual undermining of qualitative research. The better approach for marketing is to create a quantitative market segmentation informed by the needs expressed by qualitative research and personas and then referencing real people who can represent key characteristics of a segment.
In certain contexts, we have to also stop and ask ourselves whether this representation is good enough for what we’re designing. Is the relationship between an embedding of a pet with the embedding of their owner the same as the relationship between the dog and owner they were originally based on? And will our dog park designs translate into an embedding that facilitates the same experiences of said dog and owner in the embedding space as the actual designs in the world?
Often two-sides of the same coin that prompt the design researcher to ask, “why is that?”
Or anyone for that matter — hence the old joke about research findings collecting dust on a shelf somewhere.
Indeed there are a host of products and services that have dramatically decreased the cost and effort required to conduct human-to-human research in the past decade like DScout and UserInterviews to name a few.
“An [AI] mechanism that fosters users’ higher-order thinking skills during the course of task completion.”
IDEO’s Little Book of Design Research Ethics, 2nd Edition can be found here: https://www.ideo.com/journal/the-little-book-of-design-research-ethics