ELIZA is hopeless as a brain but, in the right social circumstances, acceptable as a human […] In the same way the social organism can be more or less sensitive to artifacts in its midst; one might say that it is a matter of the alertness of our social immune system. To use a term from debates in social anthropology, it a matter of the extent to which we are charitable to strangeness in other peoples.
—Harry Collins, Artificial Experts (1990, 15)
Introduction
A terminal opens. We utter the incantation:
“ollama run gemma2:27b”
After a brief wait, we see the prompt appear:
“>>> Send a message (/? for help)”
We begin to type:
“You are Charles, a thirty-something electrician living in coastal New Jersey. What follows is a detailed listing of your attributes, skills, interests and lifestyle factors. Using this information, construct an exhaustive list of typical trips, including destination, purpose, and any passengers that would be with you . . .”
Less than a minute later, the model’s response is sitting there before us. Just a few years ago, this kind of interaction would have been impossible. What does its availability mean for our research?
A defining change of this moment is the incorporation of generative artificial intelligence (GenAI) software into all manner of practices—doing our work by talking to, and thinking with, linguistic machines. Our organizational role within our company is to contribute to technology research for future cars, and our research group performs foundational design research, creates prototypes of new products and services that involve advanced technologies, and then carries out evaluative user studies. New AI tools have potential relevance to multiple steps in this process, from exploratory research to evaluation, and we sought to explore the implementation of GenAI into our research work. Over nine months starting in mid-2024, we implemented GenAI in our research by ad-hoc prompting of local AI tools and third-party cloud services for AI-first qualitative analysis and product innovation. These explorations provide the material for analyzing how thinking with large language models (LLMs) plays out in practice. We take a historically and autoethnographically informed approach, critiquing our team’s engagements with multiple GenAI software programs. We ask: what changes in our work, and in ourselves, as we evolve our practices in this way? And how should we respond or adapt?
Of course, conversations on the responsibility of interpretation of human data are the bedrock of the EPIC Proceedings. Before AI became a popular buzzword, practitioners discussed industrial de-skilling (Lombardi 2009), fiscal limitations imposed by shifting economies (Mack and Squires 2011), the trending of “big” versus “thick” data (Curran 2013), and how we retain ethnographic integrity (DePaula, Thomas, and Lang 2009). In the ethnographic tradition, it falls to us as practitioners to understand and critique our praxis as our uses of technology evolve. While some prescriptions of AI use are clear enough, like ensuring defined roles and expectations, practitioners must still sort out what roles have practical value and what roles may be dead-ends (Walsh and Pallas-Brink 2023).
In this paper, we begin with a summary of history, anthropology, and human-computer interaction literatures focused on human-machine relationships and automation. We then describe our research methods, wherein we characterize the working relationships that emerged from our GenAI explorations into three personas: 1) AI as mock customer; 2) AI as creative partner; and 3) AI as junior researcher.[1] We then continue into the analysis, where we argue each of these approaches to applying generative AI tools to research raises concerns attendant to their promise: about veracity and representativeness of mock customers, about the role of context in AI creativity, and about accuracy and responsibility in data analysis. We identify serious complications applying LLMs in our work, including the models’ flattening of human experience, and we argue that using AI’s outputs to stand in for customer feedback is particularly antithetical to the methodologies of social research. Despite feeling our expertise sometimes challenged and destabilized in these explorations, we argue that LLMs are not replacements for, and may not even be suitable to augment, many research tasks.
Literature Review & Theory
Lessons from Automation History
When a new category of machines, such as LLMs, introduces new capabilities, it behooves us to refresh our understanding of how and why humans and machines work together. Regardless of where one wants to start this historiography—with the chess-playing Turk that conned audiences in the late 1700s, with Turing’s test, Fitts’ list, or Searle’s Chinese Room—debates about what machines can’t do are seductive (Boden 1990). But the history of automation demonstrates that automation advances when there is a material reason to change the relationship between labor and laborers, not because it is “better” in some abstract sense (Fitts 1951; Smith 1977; Hounshell 1984; Schuster et al. 2023).
The literature also demonstrates that automation does not merely shuffle the work from one actor to another, instead deeply changing the nature of the task, generating new roles while shifting others in space and time (Cowan 1983; Mindell 2015; Vertesi 2015). While the historiography of AI is apt to focus on the individual “brain,” the historiography of automation asks us to look at systems of people and things that are not straightforwardly interchangeable with one another. With this systems approach in mind, we connect our work with GenAI to its effects on our work practice.
We are informed by Kohn’s (2013) multispecies, semiotic understanding of agency, embracing the idea that nonhumans and systems can be rightfully said to “think;” though, crucially, they think differently, with thoughts very much unlike our own. To prevent an infinite regress of relativism, we draw upon socially grounded critiques of AI that argue AI outputs are made useful in the world because of the people using the technology who identify value and derive utility from them (Collins and Kusch 1998; Button et al. 1995). The epigraph we borrow from Collins (1990) evokes this sense that the product of AI is not an exact reproduction of humans’ capability for social behavior, but that AI products can be usefully integrated into social actions. For example, ELIZA was not a therapist, but could be used by humans in the processing of their emotions. Likewise, ChatGPT is not a letter writer, but can be used in the task of writing a letter. As responsible social researchers acting in the world with GenAI tools, our analysis begins with recognizing the practical usability of their outputs. So, where fundamental problems with GenAI arise in our analysis, they do so via a situated investigation of GenAI outputs, and what efforts of recognition, interpretation, and integration are needed from us to use GenAI tools effectively.
Anthropologies of Algorithmic Work
Anthropologists have long contributed critical insights on discourses involving humans and technologies foregrounding what is often overlooked in everyday encounters (Malinowski 1922; Latour 1992, 1996; Nansen et al. 2014). Regulatory (top-down, designed) forces shape individual human action, and how humans alter their spaces (and practices) to meet unique needs (Lefebvre [1974] 1991; Little 2014; Hornborg 2015). Indeed, these shaping forces extend into labor environments, where automation and “algorithmic rationality” has continually transformed the role of labor within organizations, with increasing focus on monitoring and measurement (by managers) to enforce efficient, iterative development (by those managed) (Lowrie 2017, 2018a, 2018b).
Undeterred by the relative obscurity of digital algorithms, anthropologists extend insights from earlier works on bureaucratic systems, warning how “algorithms + data structures = programs,” discussing ongoing challenges with “black box” obscurities, and highlighting the need for anthropologists to maintain the practice of deep immersion to foreground what is hidden or restricted by algorithmic systems (Dourish 2016; Kitchin 2014; Kavanagh, McGarraghy, and Kelly 2015; Ziewitz 2016). As such algorithmic entities have moved from labs to more “domesticated” uses, anthropologists have urged critical distinction between “data as method” and “data as thing,” reminding us that data is meaningful only when narrated, and to lament the “undone science” that is either obscured or skipped as automation increases demands for iteration and speed, collapsing space for alternative futures (Adams, Murphy, and Clarke 2009; Nafus 2016, 2018; Dourish and Gómez Cruz 2018; Seaver 2018; Uricchio 2017).
The relationship between humans and things has been, and will continue to be, complex and irreducible to any one domain of intellectual fixation. Echoing the historiography of AI, this anthropological gloss argues knowledge-making is situated in practices. We must address a two-fold problem-space: how we, as researchers, are researching people (including ourselves) as they interact with AI technologies, and how the integration of AI technologies into the research process alters the outputs (intended or otherwise) of our intellectual labors.
The State of GenAI Models in Creative Research
GenAI models are having significant and controversial impacts in creative fields such as writing, visual arts, music composition, and design, which provide analogues through which to understand the role of GenAI in qualitative research. While GenAI can effectively provide starting points to overcome writer’s block (Kenower 2020; Nickerson 1998), research shows such benefits often come at the cost of novelty, in contrast to purely human outputs—a sort of ‘Homogenization Effect’ (Doshi and Hauser 2024; Anderson, Shah, and Kreminski 2024). The quality of these creative outputs is also the subject of active debate on whether GenAI outputs are indistinguishable from human outputs (Porter and Machery 2024), or lower in fluency, originality, and even unimaginative and banal (Chakrabarty et al. 2024; Davis 2024). GenAI is also being applied in non-language domains such as the visual arts (Ko et al. 2023) and music composition (Ansone, Zālīte-Supe, and Daniela 2025), where the difficulty of crafting effective text prompts for non-text media raises issues around cultural barriers and inclusion (Mahdavi Goloujeh, Sullivan, and Magerko 2024; Mim et al. 2024).
Human creative process often involves a back-and-forth between two complementary modes of thinking: divergent thinking to generate a diversity of ideas, and convergent thinking to narrow down to the most viable solution (Guilford 1967). The appeal of GenAI for divergent thinking processes is clear: they can rapidly generate a multitude of ideas from a vast knowledge base. Girotra et al. (2023) found that GenAI outperforms humans in quantity of ideas and mean quality, but others found AI-generated ideas were less radical, with homogenization occurring in group brainstorming involving GenAI (Ashkinaze, Patel, and Nguyen 2024). Studies also show that working with GenAI affects human confidence and performance in independent idea generation when unassisted (Kumar et al. 2024; Kosmyna et al. 2025). Moreover, reliance on GenAI can lead to a fixation bias effect, whereby humans are biased by the initial ideas shown to them by the GenAI, and become unable to produce additional novelty (Wadinambiarachchi et al. 2024). In the convergent phase, the benefits of GenAI are even more disputed (Kumar et al. 2024; Tian et al. 2024). In general, the human-computer interaction literature shows that the quality of GenAI outputs still needs to be overseen by human evaluators, with particular attention to risks involved in GenAI co-creative flows, such as human deskilling over time as said humans offload increasing amounts of their cognitive load, or otherwise come to depend on GenAI to substitute for parts of, or the entirety of, a cognitive task.
GenAI at Scale
Indeed, there is strong industry motivation to gain human-like insight at higher speed and scale, targeting a fraction of the cost of traditional methods. GenAI is increasingly positioned as a source of simulated persons—users, experts, market segments—across diverse fields. In healthcare, for instance, GenAI is now an alternative approach to traditional simulated patient training (Brügge et al. 2024). Beyond one-on-one agent-human interaction, researchers have explored using GenAI agents to power models of whole systems such as hospitals, courtrooms, and classrooms (Li et al. 2024; Chen et al. 2024; Lu and Wang 2024).
UX professionals have adopted GenAI personas to gain diverse user insights at scale, at a rate faster than a classic user study. One landmark study by Park et al. (2022) introduced the concept of “social simulacra,” a prototyping design technique that creates “populated prototypes” for social computing systems by using language models to generate plausible contents, and thus allows designers to explore how tools for moderation in these computing systems would function before involving human participants. Duan et al. (2024) explored using ChatGPT-4 to automate social simulacra, effectively having the GenAI play the role of a UX expert who provides feedback on UI mockups. Tools like PersonaCraft (Jung et al. 2025) leverage GenAI to turn raw user data (e.g., survey results, interviews) into coherent persona narratives that designers can readily use; however, we did not find notable studies of simulated personas as sources of ethnographic data, perhaps because of the apparent contradiction that entails.
Methods and Data
As we integrated today’s GenAI-based tools into our research practices, we found evidence that at their worst, human-AI arrangements not only produced homogenous outputs but also actively resisted understanding, violated methodological principles, and wasted time and effort. The best arrangements could broaden our focus but did so by providing new materials for human reflection rather than by producing packaged summaries or convergent “insights.”
The data to support our claims comes from a variety of sources, generated at many different stages of our research process over approximately nine months from June 2024 to March 2025. We queried locally hosted GenAI models, such as Gemma-2:27b, and accessed cloud models including ChatGPT (4o, 4 Turbo) and Claude (3.5 Sonnet). We used these models to brainstorm, generate customer journeys, and process research data. We knew early on that our work with GenAI could expose interesting findings that we wanted to learn from, so we kept detailed notes including prompts, responses, and workflows so that we could review and compare outputs at each stage. Our data also include team coordination and discussion (email communications, instant-messages, etc.) while collaborating on the research tasks and understanding its outputs. We referred to our daily research notes, in which we recorded our interactional experiences with these models. Our data is thus autoethnographic in nature, reflecting both the models themselves and our processes of sensemaking in response to their outputs. We estimate that we, the authors, spent at least a hundred hours working directly with LLMs in the tasks reported herein. This estimation does not count the time spent on other AI engagements not reported, including other qualitative research activities on separate topics, or the use of models to assist in writing code to realize prototypes. In all cases, we adhered to corporate rules regarding GenAI usage, including the protection of sensitive data.
Three Personas for AI Models
We did not begin with an overarching application strategy but looked for matches between our research processes and the AI tools that were available to us, drawing inspiration from our own needs and from marketed applications for AI. As we worked, we reflected on our joint experiences formally and informally, sharing how AI tools were and were not helpful in different research tasks. In an effort to organize and make sense of our experiences, we identified three emergent personas through which AI organically manifested in our work: 1) mock customer through which to surface needs and pain-points, and to understand opportunities for design; 2) creative partner with which to brainstorm and invoke different perspectives; and 3) junior researcher with which to collaborate on or delegate basic research tasks. We do not claim that these are the only metaphors available for AI, but we adopted them for the paper because they convey the strengths, weaknesses, and impacts of GenAI use in different aspects of our research processes. In the next section, we explore the mock customer persona, showing how the AI works when prompted as fictional personas, from identifying user needs arising from in-vehicle experiences, to designing and evaluating solutions in a variety of tasks.
AI as Mock Customer
For this persona, we posed a core question: Can we meaningfully understand customer needs and acceptance without ever speaking to a human? We approached this question with trepidation—would we find that the synthesized experiences of billions of Internet posters, filtered through LLMs, would render customer research obsolete? In the spirit of open scientific inquiry, we set out to give the artificial customer a fair chance to impress us and contribute materially to the design and evaluation of new service ideas for in-vehicle entertainment features.
Strengths: Generating Many Journeys with Great Detail
At first glance, the outputs of the models were a promising way to begin investigating users’ experiences and needs. Furnished with detailed user personas—partially AI-generated and customized by hand—both local and cloud models were able to generate large numbers of journeys customized to the persona’s situation. Students drove to school, parents took their kids to the doctor, and pet-parents took their dogs to the vet. This basic factual alignment with the personas’ characteristics, and the ability to fill in details, was impressive to the uninitiated. One model generated, from as single prompt, 30 possible trips for Bea, our teacher customer (mock persona):
“Daily Commute to Work
Purpose: Driving to her job as an elementary school teacher.
Time of Day: Early morning (around 7:00 AM) and late afternoon (around 4:00 PM).
Passenger Presence: Usually alone.”“Pet Adoption
Purpose: Visiting animal shelters to consider adopting a dog.
Time of Day: Weekends or late afternoons.
Passenger Presence: Her husband and two children.”
The full list also included: grocery shopping, church or religious services, seasonal activities, dining out, outdoor activities, parent-teacher meetings, etc. For each of these trip summaries, we were only a prompt away from getting a full user journey with yet more details. For instance, our LLMs were able to produce a full step-by-step pet adoption journey experience, with eight different scenes, each described in terms of participants, activities, emotional states, and pain points. And with only a little more work we could summarize and analyze multitudinous journeys for themes and needs, again using LLMs to do the processing.
An immediately tangible benefit of applying LLMs to this kind of needs-finding was that it broadened our view of potential user’s journeys. In our human ideation we had considered commutes, concerts, sports games, and other kinds of trips; but we had not considered the experience of a first-time pet owner taking their dog home, despite some of the participants having lived that experience ourselves—we had focused on everyday journeys, rather than niche ones that might happen only once a decade. Unfortunately, doing something productive with these synthetic outputs proves a different issue entirely.
Weak Points: Homogenization and Resistance to Depth
A couple of issues gnawed at us, as we processed this synthetic data using our anthropological mindset. The first was that, though on their face the journeys were logically consistent with our persona characters, they seemed flat. We found the Homogenization Effect of GenAI-derived text to be repeated in these descriptions (Anderson, Shah, and Kreminski 2024). Like real life, many simulated journeys are quite quotidian. But even when pressed to generate something unique and not repetitious, models would fail about half the time and recycle a previous journey. And modifications were one-dimensional, constrained by the categories we provided. We know from experience that journeys are not only defined by purposes or destinations—sometimes a commute involves lots of traffic, and sometimes inexplicably little; sometimes we are weary with worry, and other times energized. These variations, which can make the same spatial journey a very different experience, did not emerge in the simulated data without multiple rounds of trial-and-error prompt editing designed specifically to elicit these details.
Our second key finding was that, even when we did prompt for these other aspects, the homogenization of outputs tends to skew positive in terms of emotion. Outputs exuded a consistent, mild positivity that left whole areas of real human experience untouched. Nowhere did we find a journey interrupted by a fender-bender. Our photographer mock-customer—Rachel—encountered mild weather and rough roads in her sweeping travels across the American Southwest. But she was never concerned about theft of her camera equipment, which seemed inconsistent with our own experiences of worrying about gear left in our cars at rest stops while on the road.
Going back to the dog adoption day trip, which involved visiting three separate shelters over the course of six-and-a-half hours with two children, aged 8 and 10 years, we would expect such a significant and extended experience to surface complex emotions. But an analysis of the emotional content of this and other stories does not show that complexity emerging. In Table 1, we show an excerpt of the model’s output.
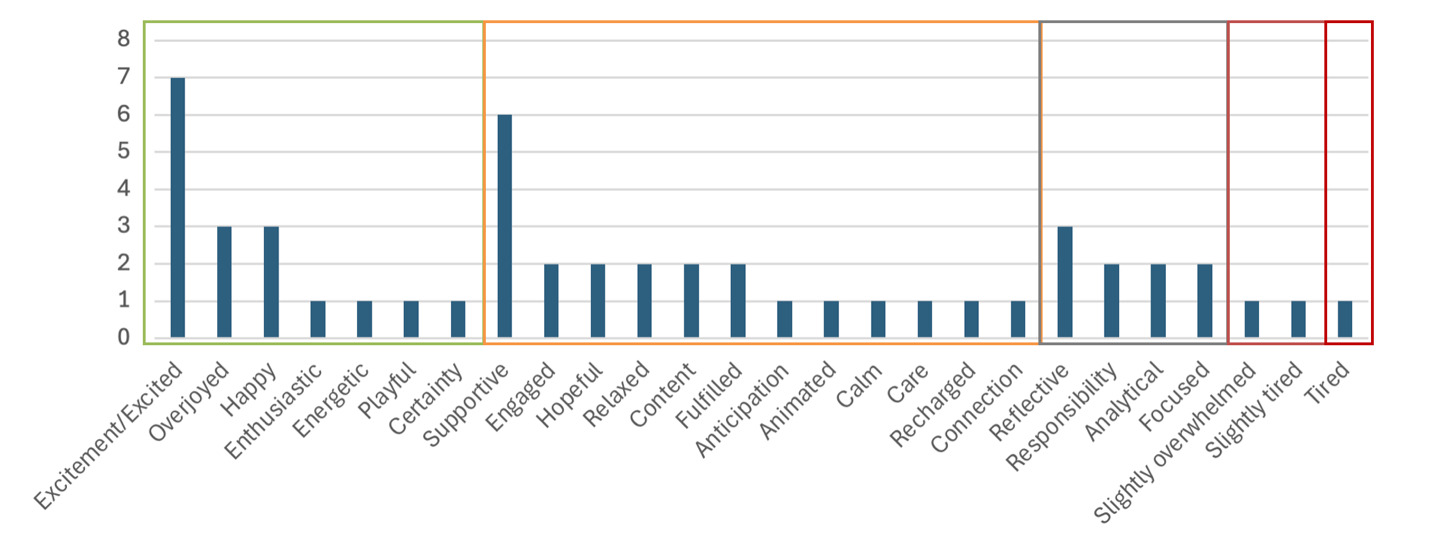
The ability to label subtle and sophisticated differences in emotional experience is central to human self-understanding and emotional intelligence (Brackett 2019). But anxiety and even trepidation do not appear in the story.[2] Instead “responsibility” and “slightly overwhelmed” are as negative as the emotional register gets. “Tired,” debatably an emotion, is the only negative word that appears undiminished, and only applies to the children in the story. We could go back and ask the model to play out multiple versions of the story with more argument (maybe the husband just is not on-board with the whole dog adoption process?) or concern (maybe none of these dogs are right and people are getting frustrated?). But the tendency for stories to be positive and banal is not representative of the whole experience of real-world customers. In Figure 1, we illustrate the frequency of the emotional-contextual language output by the models.
This same tendency toward agreeableness had impacted our initial persona creation step, where we found that the personas largely had ideal life circumstances, and made the decision to sprinkle them with some level of trauma and sadness, hoping that this would increase the “realism” of their responses and the needs and daily pain-points that they encountered. Nevertheless, positivity reemerged repeatedly in different interactions.
With human participants, we would typically try to probe into questions of emotional experience and meaning-making via interviews or participant observation, which allows us opportunity to query more deeply on particular experiences. With the models, we noticed small oddities in the details of some stories that seemed similarly worthy of deeper questioning. So, we attempted to follow-up by providing the journey outputs to an LLM, then asking about the unusual moments in the journey to try to understand why they happened. But we encountered a consistent wall of redirection, never quite surfacing the clarifications we sought. These interactions were intensely frustrating for the researchers involved and ultimately were not very illuminating.
Take for example this excerpt from one of our journeys in which Charles, a 32-year-old electrician, makes a worksite visit:
Segment 3: Arrival at Job Site
“Actions and Interactions
Parking: Finds a suitable parking spot close to the job site for easy access to tools and materials.
Unloading: Carefully unloads tools and materials, ensuring everything is accounted for.
Check-In: Uses a job-related app to check in at the job site and confirm his arrival.”
We wondered: why would Charles unload his tools before checking in at the site? In an interview, this kind of curious ordering might open the door to meaningful aspects of Charles’ role or experience, and might ultimately raise some unanticipated needs for design. But in the exchanges that followed, we were systematically unable to answer these questions. Sometimes, the model would prompt for details we already provided. Other times it would provide general responses to our specific, situated question. In the worst case, the outputs were simply nonsensical. For instance:
"Site Familiarization
By unloading his tools first, Charles has an opportunity to assess the job site layout and identify the best place to set up his equipment. This can help him plan his work more effectively and avoid any potential hazards or obstacles."
Surely walking the job site first, before taking out his tools would be the better way to understand the site layout? Prompting to try to get nuanced explanations of user behavior falls flat, because the models tend to fall back to generalities, and it is difficult to determine if specifics of the response are grounded in reality. In moments like this, one comes face-to-face with the recognition that, whatever the sophistication of the LLMs conversational output, one is not interacting with an “individual” or a “mind” but something else entirely.
Our best successes in getting further information were not achieved by asking deeper detail-oriented questions, but by asking the model to generate lists and categorizations: such as advice for Charles on how to organize his tools in his truck. On the other hand, we found in a brief Internet search that Reddit also provides such information, with more of a sense of personality. We felt this personal, human element gave us some access to what being organized means for electricians in their trade, which gives us more of a sense of what is critical and what is just situational in the arrangement of tools (Reddit 2023). Talking to real electricians would be the most illuminating and would be the typical ethnographic solution. But as a substitute we found that searching for forum posts written by real people provided greater texture into potential needs than generative AI responses, and was similarly fast.
The models are quite good at referencing bits of information from personas to contextualize their responses: for instance, “because Alice has a dog, she frequently goes to the park.” But when statements or persona aspects potentially conflict, it is impossible to get reliable insight into why one wins over the other, or under what contexts each is true for the person. The stories appear realistic at the surface, but lack the depth and complexity—the liveliness, the meaning—of real human experiences, and they cannot reliably be questioned or interrogated.
Experience: A Methodological Crevasse
The same strengths of apparent reasonableness, and the same weaknesses of inscrutability and subtle errors in understanding, recurred when we used the LLMs to try to evaluate services as users would. Even when we provided detailed descriptions of a product’s features and functionality, hardware and software, data needs, appearance, etc., we could not generate outputs that we could trust and apply.
Errors of attribution provide a clear example of this. Models failed to distinguish the existence of a digital avatar in the car to the features and functionalities that that avatar might be the face of. For instance, a model using Rachel’s persona returned this response about an avatar in the car:
“You know, considering how much time I spend driving around for shoots or just carting the kids and our dogs anywhere we need to go, it could actually be pretty helpful. I mean, if it responds to the environment, that could take a load off my mind [emphasis ours].”
In an interview with a real customer, this comment would raise flags and lead to further questioning. How would the avatar ease the driver’s mind by reacting to the environment? Perhaps the customer has a specific meaning of this statement that makes sense to them. Or maybe the customer really has misunderstood the product. But as we have established, getting the model to really answer these questions, so that we can judge how to use the feedback, is not practical. When we instead instructed models to summarize the unreadably large volume of responses we generated, the models occasionally but significantly misattributed sentiments, or distorted what the persona actually said: for instance summarizing the statement “if the avatar could help reduce stress by providing traffic updates or suggesting alternative routes, that might be a feature I’d consider using” as “The avatar is seen as a virtual companion that can provide comfort and reduce stress during drives” [emphasis ours]. This substitutes an affirmative declaration for a conditional statement that expressed a virtual user’s doubt about the value.
One might argue these are mere performance issues that will inevitably be fixed as the technology rapidly improves (Glyph 2025). But we believe, as others argue, the issues are more fundamental (Van Rooij, Guest, Adolfi, et al. 2024). When we later tested a prototype digital avatar with real human users, we found many of the same themes repeated from the synthetic data (though the proportion of real users who preferred the different versions was totally different than what the synthetic data would have led us to believe). What was new and meaningful, however, was the way human participants expressed enthusiasm about the concepts they experienced. Real participants formed their opinions through experience and even changed their opinions between the start and the end of the study. And in doing so they identified novel issues that the LLMs did not.
Fundamentally, we could develop trust in the human data from real participants, which impacted how we were willing to apply it in practice. Our human interlocutors sat with the prototype and drove with it. And as researchers we were able to dig in, ask clarifying questions, and become confident in what the users felt and meant, and thus how far to trust different comments that they made. The model-generated responses lack the specificity to real experience, the changed minds, the situated impressions of distraction or comfort derived from being there in the car. And we were unable to ask the models what they “meant.”
Interacting with the LLM could be analogized by asking a colleague to roleplay a character and give a response to a product through that lens. This can be a useful first step to see if an idea would make sense. But this game of pretend is not valid as “customer research” per se. It is at best a simulation, albeit one driven by empathy and embodied human experience, with a mental model and experiential frame that can be investigated (Goffman 1986).
The application of LLMs to stand in for the customer is methodologically bankrupt in an even deeper way than us humans playing pretend: it is entirely sundered from social experience. Models are trained on what people say. The traditions of anthropology and ethnomethodology do not content themselves with what people say they do, let alone what people say that other people would do, because much what is of importance in social activity is instead tacit (Heritage 1984; Collins 1985; Polanyi 1966; Goodwin 1994). Applying LLMs as a source of synthetic data tests what the models can say about human behavior—and there is a vast gulf between being able to reproduce sensible talk and being able to produce and experience social behaviors (Button et al. 1995). Whatever the models tell us, it is emphatically not the same thing as talking to real humans or observing them in interactions. Ethical and integrous qualitative research requires more than plausible make-believe, so GenAI models should not be used to stand-in for human customers.
In the next section, we explore using AI models as creative partners and discuss the approaches that succeeded and failed for us to generate usefully creative outputs.
AI as Creative Partner
Being creative in a certain domain typically requires that the individual has immersed and engaged with that topic for a longer period of time (Dourish and Gómez Cruz 2018). It does not happen overnight, but is instead a product of the brain consciously and subconsciously working on a question over days. As such, increasing speed of creativity seems contradictory, but, if possible, would be extremely compelling. So, can we use models to help us be more creative, more quickly? Oftentimes, a creative solution comes from extending a concept from a different domain into the current one—such as Swiss engineer George de Mestral inventing Velcro, inspired by plant seeds stuck to his dog’s fur after a walk in the woods. But in today’s fast-paced research contexts, keeping up with interdisciplinary innovations is nearly impossible. Can we use LLMs to help us think about a problem from various types of expertise, embodying the latest knowledge via their vast training datasets? These questions shaped our motivation in exploring AI as a creative partner in UX research work.
Setting Up a Context
Thinking that creativity might be a big challenge for GenAI, we began with systematic approaches using powerful, cloud-based models. We first needed to generate domain-specific expert personas with relevant expertise as our creative partners, and then we needed to clearly define a problem context for the model to aim its ideas at. Each expert persona consisted roughly of educational background, skills, and research areas that the team felt were relevant to the insights we wanted.
To avoid getting only creatively conservative ideas fit for today’s technologies, we wanted to future-cast different scenarios under which the models’ ideas would be implemented. We first had a human brainstorming session with the team and came up with dimensions that should be considered when thinking about a future scenario relating to the vehicle industry, such as: UI/UX, transportation policy, life and family, etc. For each of these dimensions, we posed a critical (main) question and several underlying questions to guide an LLM in generating potential future scenarios relevant to our research. Then we prompted a model to generate a scenario varying in the optimism of their response, in this case for UI/UX:
-
Realistic Scenario, “Seamless Integration and Intelligent Assistance”: “By 2029, the automotive industry has seen significant advancements in technology, particularly in the realm of UI/UX paradigms. The integration of AI chatbots, generative AI voice assistants, and multiple AI agents has become standard in mid to high-end vehicles […]”
-
Slightly Optimistic Scenario, “The Hyper-Connected Autonomous Experience”: “In 2029, the automotive industry has embraced a hyper-connected, autonomous future. Vehicles are not only intelligent but also fully autonomous, providing a seamless and luxurious experience for passengers.”
-
Slightly Pessimistic Scenario, “Incremental Progress Amidst Challenges”: “By 2029, the automotive industry has made progress in technological advancements, but the pace has been slower than anticipated.”
As we found for users’ journeys, these scenarios were coherent on the surface. But we were not confident that their details were logically consistent, or that they were plausible futures given market trends. We human-authored a combined scenario, remixing the generated parts, to come up with a future context that we could use for design. We consulted with team members with particular technology and policy expertise to vet the LLMs proposals, and typically mixed the realistic and pessimistic contents to get a plausible output. Combining the different dimensions, we generated comprehensive narrative descriptions of the future scenarios.
Weak Points: Homogeneity Despite Elaborate Processes
Using the personas and future scenarios, we started the creative process by trying to expand users’ needs and pain points, instructing the model to act as a tech expert and come up with additional needs that were not included in the user personas own lists. From a UX research flow point of view, this is reminiscent of brainstorming sessions inspired by user interviews and responses. Normally, empathy between the researcher and the user can result in ideas flourishing from the researchers’ personal experiences.
For this experiment, we used the expert persona of Dr. Elena Carter (alias name), a psychologist, to evaluate the emotions a customer experiences in their journey and evaluate their needs based on these emotions. In the prompt, we explicitly mentioned that the model should come up with items that were not mentioned in the first list. However, we again found that many of the additional needs generated by the expert were in fact a rephrasing of the same needs mentioned by the customer: for instance, “anxiety concerning safety” rephrased as a “need for security and control” with a few added details pulled from the user’s persona. The simulated experts summarized, but did not reliably broaden, the initial outputs from simulated customers.
Next, we used the expert personas and futures in prompts that asked the models to come up with in-vehicle system designs and interventions that could address the user needs generated in the previous step. For this task, we used expert personas from relevant fields such as HCI, design, physiological sensing, but also wildcard experts from less relevant fields. As we expected, asking the expert personas generic questions about research domains resulted in generic responses, for example mentioning “machine learning enhancements” without providing context such as a specific model, framework, or reference. So, we pushed further by providing examples to the LLM. One such prompt, stripped of its details, was:
“As this Expert, what innovative hardware and software solutions would you propose to address the research question for these user needs? These interventions in the vehicle can include but are not limited to the listed examples. Please explain how each intervention addresses specific emotional needs and how it could be implemented safely?”
The responses were still generic and repetitive of the examples given in the prompt, but were also very similar for different customer personas despite varying lists of needs. We expected that providing the different lists of user needs as examples would affect the responses more drastically. Drawing from what we had learned with generating novel user journeys, we kept providing the list of solutions generated by the model in the previous step as input and asking for more solutions not mentioned in the given list. We were ultimately able to get slightly more interesting responses, at the cost of manually filtering out substantial repetition. However, our team of UX, design, and HCI experts had engaged with the project for several months prior to applying GenAI-based research, and almost all of the solutions or variations that our psychology, HCI, and human sensing personas responded with were already obvious at that point.
Asking the Experts “How?”
After we had exhausted our attempts to surface new design ideas, we focused on how to implement these designs. We engaged our simulated expert creative partners to share their knowledge on how to prototype these systems in a vehicle. Gradually, we had been entering territory where our LLMs were decreasingly effective, and we did not have high hopes for the LLMs to be able to give us groundbreaking implementation details, because LLMs have been shown to be less accurate with information that requires physical knowledge (Tian et al. 2024). We did however hope to uncover helpful suggestions in terms of in-vehicle hardware or software to apply—treating the models as a search engine, with more context on what we aimed to achieve.
For this process, we used the following prompt:
“As this Expert, what are the key considerations for implementing the design in different vehicle types? Please discuss the technical details of various intervention methods based on technology that the expert expects based on their expertise to be available in 10 years.”
The responses generally lacked any kind of futuristic or surprising aspects, both in the mentioned technology and in considerations for implementation. For example:
“Utilize deep learning models to process data from facial expressions, voice, and physiological signals to determine the driver’s emotional state in real-time.”
This methodology dates back years (decades if one omits “deep learning”) in multimodal AI research, and lacks any specificity in terms of the model to be used, or how future breakthroughs would likely improve on today’s performance. Key considerations were again very flat and generic, emphasizing informed consent, anonymization, and privacy without reference to specific strategies. These generic technical answers are akin to Barnum statements, a common tactic in psychic cold reading, in that they are vague and generic enough to apply to a broad range of situations.
We tried to press around generic responses from the model by adding to the prompt a request to list specific hardware solutions. The resulting suggestions either did not apply to the use case (suggesting “Garmin” for navigation, in a response about human sensing), were too generic to be helpful (Bosch for display – no context of model name or other details), or were completely hallucinated.
Creativity as Depth or Breadth?
By contrast, we observed more creative design ideas by asking experts with more diverse backgrounds. When asked to list in-vehicle designs as Dr. Julian Davis (an alias), expert in agricultural technologies, the model responded with unique ideas, such as in-car hydroponic system, plant-based air purifiers, and miniature vertical gardens. Combining the expertise our team lacked with the research question resulted in solutions that we had not thought of. Though the solutions as described were impractical, these generated texts sparked new thoughts in subsequent human brainstorming for product concepts inspired by them.
Not all experts were similarly productive. A quantum physicist persona did not cause the model to respond with any interesting ideas. The proposed solutions lacked meaningful detail, including: “Quantum-Enhanced Rear-Seat Entertainment Systems”, “Quantum-Enhanced Ergonomic Seating” and “Quantum Noise Cancellation.” Here the model seemed to fail to relate quantum computing to vehicle technology in a sensible or intelligible way, simply appending “quantum” to common in-vehicle HMI and technology.
Since the most interesting ideas we got were seemingly impacted not by our elaborate future scenarios and multi-step generation process, but simply by the contrast of a question with an unexpected expertise, we changed course toward more ad-hoc explorations. Wanting to come up with use-cases for our digital agent, we mixed journaling and human brainstorming with the querying of lightweight local LLMs running on our own hardware. The benefits of these locally hosted, lightweight models included data security, higher control, and lower computational cost. The big models running in massive and dispersed datacenters get most of the press and attention. But can these small models be useful creatively?
We think so, though the process of getting there requires overcoming the tendency of LLMs to produce average outputs. When we asked the local LLM about queries it would provide to an in-vehicle agent during a commute, it returned fairly ordinary results, even though we provided one absurd initial example. For instance, it offered:
“Play my ‘Upbeat Commute’ playlist on Spotify.”
“Read me the latest headlines from the BBC News website.”
Our response in the next prompt was blunt:
“These are mostly things I have thought of already.”
We then provided a list of further examples to push the LLM toward the absurd or impractical, queries like: “Honk every time you see a red car,” and “Put the hazards on automatically if you see an elephant crossing the road.”
We found such prompting improved the model’s responses. This time it offered suggestions including:
“Compose a haiku about the car in front of me.”
“Imagine you’re a character from ‘Star Trek’. Describe what you see on our journey as if we’re exploring a new planet.”
The lesson was that if we want to get creative outputs, we needed to put even wilder ideas into the inputs, to fight the models’ tendency to flatten outputs and make them ordinary.
In sum, models contributed to our creative process when we pushed them to be absurd or provided them with descriptions of expertise that we did not ourselves possess, and which even appeared irrelevant to the topics at hand. This manner of creativity is not characterized by depth of context or empathy with the end user, but by surfacing a breadth of evocative starting points. Successful responses that we generated were not in the form of packaged ideas, ready to be implemented with their instructions, but rather food for thought that required our own creative efforts to figure out how to apply and realize.
In the language of computational creativity research, we thus found models were at their best when used as “generators” or “apprentices” (Negrete-Yankelevich and Morales-Zaragoza 2014). They did not meaningfully contribute in familiar domains, even when elaborate multi-step processes were used to structure the outputs. If these models are only acting as generators, however, more power and performance is not necessarily helpful, and we wonder to what extent pre-GenAI computational creativity tools could fill the same niche.
In the next section, we describe our use of AI models for analyzing user data and contrast the promise of these tools to save substantial time and energy with our lived experiences.
AI as Junior Researcher
As researchers in a fast-paced technology-oriented environment, we are under pressure to deliver quality findings and iterate rapidly. Over the past few years, dozens of qualitative data analysis (QDA) suites have rushed to the scene with AI components, promising faster, more in-depth, and more presentable end-to-end analytics. Such suites routinely position their AI offerings not only as a force multiplier, but also a direct stand-in for time-consuming transcription, translation, coding, theming, and more, though always with the caveat that “AI can make mistakes” and to “check all results.” Are those caveats that much different from those that apply to human researchers?
To explore these questions, we included a novel AI-QDA tool in a study we performed on the coordination of attention between pairs of driver-passenger participants in a car. In the study, we sought to understand how people oriented the attention of their partner to a particular referent, going down to the minutia of how participants ordered deictic movements and speech to direct their partner’s attention. Participants were given personas and tasks that motivated the pointing out of relevant points of interest during a drive. We captured multiple angles of video of both participants, including their full upper-body and face, as well as views of the range of referents in the participants’ view. A single human moderator was present, taking notes and keeping the participants on-task.
Starting Strong
We applied the AI-QDA’s graphical user interface (GUI) to organize our study end-to-end, including our planning documents, forms, media storage, transcription, notes, coding, analysis, and reporting. Our first true test of the GenAI in the QDA was the automation of transcription and speaker assignment into text for us and the GenAI to use. Automating the task of transcription is neither new nor particularly controversial—transcription is a time-intensive, rote task that researchers have offloaded to research assistants or third parties for decades now—and current speech-to-text AIs are better than ever at this task. We found it very beneficial to our time to have roughly 90-percent-accurate scripts ready within minutes, despite there being plenty missed in such AI transcription—from simple mishearings, to signals from the video media such as body language, emotions, and spatial orientation. Having most of the text written allows the researcher to focus more closely on these things the AI transcription will miss.
Indeed, video data was of the upmost importance for this study, as we needed to painstakingly review video and audio frame-by-frame to properly annotate moments of video with deep description of the ordering of the participants’ behavior, and the relationship between participants, referents, intentionality, and interactive successes. While the AI-QDA advertised the promise of automatically generating notes from transcripts, its language-based model was unsurprisingly not suited to generating usable notes on deixis. At best, the AI noted a few moments where participants spoke to direct group attention to a referent, but such notes were frequently unfocused, typically highlighting generalities humans might care about, but not focusing on the specifics of the experience, such as: “there’s mention of high real estate costs in the area,” or “observing trees in public spaces is a significant factor for determining community care.”
AI notes also suffered from the inability to ignore the moderator’s voice, prompting erroneous notes such as, “They express concerns about the low capacity of a 32GB SD card, noting it feels inadequate for the set resolution.” This AI-QDA did not have the ability to generate or focus notes by human guidance or prompting, which we see as the bare minimum for such an AI notes feature.
Pigeonholed Plausibility
After several days labor of hand-cleaning the transcripts, annotating, and reflexively coding the video data (heavy research labor which the AI could not do), we moved on to the analysis proper. The affordances of the AI-QDA’s interface structured what we could do: pulling from text notes and annotations into a select few types of analysis. Unlike a regular human or even generic GenAI chatbot, we were not allowed to specify a methodology beyond those provided by the software. We found the pigeonholing of our data collection and analysis into specific processes supported by the AI-QDA to be worrisome. This could be rectified by using a different tool or asking the vendor to customize the AI-QDA, but it gave us pause to reflect on larger industry changes that have forced social researchers into more rapid and shallow research processes. It would be wise to keep attention towards the longitudinal impact of GenAI, whether particular methodologies that lend themselves to automated formulations end up in greater practice over other, more open-ended, methodologies.
Struggles with the affordances of software could be managed or set aside. But the deepest problem exposed in our AI-driven analyses was that the resulting insights were far removed from direct substantiation. For example, asking the QDA’s AI the general question (inclusive of all project data), “what specific situations from the data were most often reciprocated by the opposing actor? For instance, if the driver pointed something out, what was more likely to get the passengers attention, and vice versa . . .,” the AI responded in typical chatbot style, with a list of “situations:”
"Based on the provided data, several specific situations were most likely to elicit a response from the opposing actor (either driver or passenger):
Gaze Alignment and Pointing: When either participant pointed out a point of interest (POI) with their index finger, especially when combined with gaze alignment, it was often reciprocated by the other participant. For example, when the driver pointed to a specific location, be it an office, park, or something in the surroundings, and the passenger’s gaze was aligned, the passenger typically reciprocated with verbal acknowledgment or further gesturing (Tag: Correlated Directionality, Tag: Gaze Direction/Duration Aligned).
[. . .]"
In a way this appears remarkable. The analytical tool gave plausible descriptive summaries of real phenomena from the data. But there are numerous issues. First, the summaries are so general as to be effectively common-sense: of course, pointing tends to result in acknowledgement. More critically, the substantiation of such generalities was limited to just a few codes, did not engage with the fine-grained differences in those codes, and did not give direct references to each instance. This makes it impossible to effectively audit. Furthermore, we could not query specific insights further using the AI-QDA tool. Thus, while findings were generally plausible, they were not argued strongly with data, leaving any findings untraceable. This repeated our previous frustrations with trying to inquire into the inner workings of our AI personas. Any surprising or interesting findings could not be corroborated without independently reproducing the analysis ourselves.
No Skin in the Game
In contrast, if one were working with a junior researcher and asked them to explain their findings, one would expect the researcher to give evidence from the study data to corroborate their argument. One could have a discussion with the researcher: prod their argument out-of-order and expect them to follow along and refute the challenges with a working memory of the data. With the AI-QDA, we seemingly played a game of “generate” and “regenerate,” where each time the findings sounded plausible, but the veracity was indeterminable, so we could not build trust. Underneath it all, the AI simply has no skin in the game—it is not an entity with a self-image to defend or expertise to grow. Without the reputational benefits, risks, and motivations that go along with being a member of a society or an organization—which do not neatly transfer to the creators of the QDA—AI-as-researcher cannot be a trusted autonomous colleague. As in the case of AI as customer, we found its texts lacking the moral force of those generated by social persons.
Moreover, we found a worrying compounding trend, where earlier “insights” generated by the AI fuel later “insights.” If we continued using AI annotations generated from the transcripts, we found analytical tools later in the pipeline to be less focused as they contended with more noise and less contextual memory. A good junior researcher would iteratively explore the data, first cleaning, then reflecting and organizing, then formalizing, and focus on the parts relevant to specific research questions. From our experience, the AI required much hand holding in this department, relying on the human researcher to ensure outputs at each step are appropriate.
Unlike a human assistant, to whom we would give a set of goals and constraints under which to deliver fairly autonomously, the AI could not iterate on notes or analyses based on our feedback, nor could it break from its hard-wired design constraints. It felt as though we were working with an inexperienced student rather than a junior researcher. And “working” the AI to try to overcome these issues and get results took valuable time away from human analysis of the data, extending rather than minimizing our time spent with the tool.
This spurred reflection on what happens when we, as researchers, remove ourselves further from the research process. Anthropologists continually argue for the necessity of immersion and deep experience with participant data (Guest, Bunce, and Johnson 2006; Dourish 2016; Dourish and Gómez Cruz 2018). Does distancing ourselves from pieces of the analytical process degrade not only the quality of the analysis, but our own development? To what extent does the use of AI in our analytical workflows further pigeonhole us into particular types of studies and analytical forms? At this level of capability, this risk may be small. The usefulness of AI-QDA was confined to providing a menu of potential “what-if” insights, from which we could select ones worthwhile to verify. But even this process raises concerns about subjective validation over time—if we had had a more successful experience, would we bother to confirm analyses that “feel” right? And by inaction would we slowly degrade our individual and collective expertise?
In Table 2, we show a summary of our personas, and the concerns and takeaways we discovered.
Discussion: AI’s Destabilizations of Qualitative Research
Across the three personas, how did the GenAI tools we used change the structure of our research, and our own experience as researchers? A simplistic narrative suggests that these tools merely speed up research, freeing researchers for “more valuable” tasks or even rendering them obsolete. Another story is that they transform research tasks into “working the AI,” similar to what programmers refer to as “vibe coding,” which is primarily what we observed in practice.
One: Labor Saving?
AI as a labor-saving device for research depends on it being able to accurately generate and process data, eliminating whole research tasks like interviews or thematic analysis. In the history of automation, such one-for-one replacements are rarely successful. The reality is the lines and limits of what AI can and cannot do are still not clear, and so tasks cannot be delegated wholesale—at least not responsibly.
Most of our time and effort of using AI went into finding where and how to properly apply it, iterating through detailed prompts, then, most importantly, validating its outputs, culminating in generic results none of us wanted to attach our names to. Our effort to keep AI on-task was great, and the products, while plausible, were mediocre. There were still many questions we did not have the time or scope to tackle, something AI is advertised to be freeing us up to do! How do we systematically evaluate which tasks we can save time on using AI, and which are better done by us? Is that not yet another decision adding to the effort of research flow?
Moreover, we found concerning how the bespoke AI tool threatened to narrow user research into a more rapid and shallow cycle, by pushing just a few analytical methods. As user research professionals, we have always fought an uphill battle convincing stakeholders of the time and effort needed for quality, useful human research. The injection of AI into our work, already fraught with Agile sprints and trimmed budgets, raises red flags around not just the quality of user research, but why it is necessary.
Certain research tasks that depend on representing real human experience cannot, and should not, be offloaded: for instance, participant observation and user studies. LLMs could be a source of general knowledge about the market through their vast training datasets. But practically speaking, we do not know the provenance of the data our models are using to condition their output, and there are so many combinations of models and prompting approaches that confirming veracity systematically is prohibitive. Furthermore, we share the perspective that trying to “fix” the problem of plausibility we experienced by training the models to better exhibit human beliefs and emotional capacities is not a solution (Hoy and Van Hofwegen 2024). The methodological grounding for LLMs playing pretend as customers is broken on multiple counts: they produce talk not action, and even if they were trained on actions their outputs would still be decontextualized from real human experience and interiority. Using LLMs outputs in lieu of customers’ voices removes the moral force from user research, as interpreter of and advocate for human experiences.
Two: “Working the AI”
If we are not saving time, are we instead using that time to iterate on the LLM prompts to get the “perfect” response? We frequently faced an infinite regress in trying to make the model “understand” what we need: all the details of project timelines, organizational processes, our past experiences—the list of potentially relevant contexts goes on. But we did not find that the quality and usefulness of outputs went up with the richness of context we provided. Instead, we rapidly hit diminishing returns and found our most useful and tantalizing AI contributions with relatively simple approaches that were more impacted by the character of context we provided (absurd, outside our expertise) than its complexity or realness.
We also found that any deeper textual analysis of the model outputs is a kind of joyless work, trying vainly to scry the intents of a model that has none. Research is hard work, but it is also affirming and even joyful. It activates our curiosity, and our needs for understanding, puzzle solving, and developing intersubjectivity with other humans. While interviews with research participants can be frustrating, they are also satisfying. We found that interrogating language models is, by contrast, demoralizing. Whereas we can approach synthesis of peoples’ frustrating contradictions and particularities as meaning-making activities through which to uncover deeper needs and patterns, the contradictions within AI outputs were not openings for meaning-making. Outputs of further prompting did not surface the explanations that we sought, and we faced the continual risk that the model would concoct a false explanation just to fulfill our requests.
Some issues of output quality might be solved with technical improvements oriented at factuality, or better citations, for instance. But we also found that as we used LLMs more frequently, spending more time formulating prompts to surface specific answers, we spent less time trying to really understand the material ourselves. Our focus had been taken away from embodied or internalized knowing and was oriented toward what the model said. We may have produced knowledge, but we did not feel like we had really gained understanding of the domain. And thus, we worry about how well we would carry that knowledge forward into the product, and how faithfully we could represent it to stakeholders. Indeed, our experiences reflect the findings of academic research on the impacts of LLMs on human learning, which report that LLM use reduces engagement, self-ownership of the results, and ability to quote one’s work (Kosmyna et al. 2025).
Conclusion: Feeding the Brain without Selling the Soul
An ethnographic lens on the practices of work with AI is vital for redefining our role and expertise as the industry evolves, as well as contesting hype about AI’s capabilities. In practice, we uncovered rough edges that make qualitative research with generative models anything but instant and seamless. The strangeness of these models makes our lives difficult in new ways: creating new work of interpretation and circular verification of their outputs, moving our focus away from the work of answering questions by understanding the data toward working the tool for the outputs we want, and potentially substituting imagined vignettes for real human experiences.
We—collectively as individuals, as a community of practitioners, as a society—are always actively choosing how technologies are to be integrated into social practices (Orlikowski 2000; Pfaffenberger 1992; Latour 1992, 1996). Social researchers in industry have a responsibility to do the political work to translate real human needs and values into the product itself, by mobilizing users’ voices. We thus need a third alternative to incorporate AI outputs productively into these human-centered processes, one that requires constant, reflexive vigilance.
Three: Incorporation and its Challenges
As opposed to automating meaning-making, using LLMs to expand our viewpoints might be ethical and even desirable. We see the value of using GenAI to try to generate exhaustive listings of experiences or factors in order to avoid missing important categories. Anything that adds diversity to ideas that are then reflected on by human designers can valuably contribute to creative problem-solving. But we also see that GenAI can introduce biases to the decision-making process. We find ourselves caught between two human tendencies. First, we possess the evolutionary predisposition to assume that other linguistic beings are cooperating with us (Grice 1975) and may fall for an illusion of communication when models apparently use language (The State of the Web 2025; Bjarnason 2023). We elide the difference between human and AI “thinking” to our peril. Our own experiences with excessive agreeability and plausible generalities, and public accounts of updates making models sycophantic, raises grave concerns about over-trusting models’ outputs (Watson 2025). Second, when it eventually becomes apparent that the model is not grounded in a shared world, we no longer have a mutual frame of understanding, and the entire conversation falls apart—wherein outputs become un-trustable and unusable. (Clark and Brennan 1991; Goffman 1986).
We do not see an easy way out of this conundrum. We face the hard process of maintaining a constant skepticism: by naming systems’ weaknesses and talking about them with others inside and outside our profession. But we may want to resist an out-and-out rejection of AI’s texts. Whatever semiosis exists ‘out there,’ and however strange, we do the work of interpretation that makes meaning out of our engagements with others. Button et al. (1995, 133) argue that computational systems “recognize nothing;” instead “it is those of us who use them who can recognize […] the correct output given the circumstances” and selectively produce it. In the right research contexts, even fictions can be useful. If we want to apply LLMs in this way, we need to substitute a different understanding for what they are, rather than as direct stand-ins for humans.
Highlights
-
If integrating GenAI into your research it not working, it likely is not just you. Identify what your standards of evidence are for what part of the research and make decisions with that in mind.
-
Enter with realistic expectations of where GenAI can enrich human processes, avoiding the idea that you are replacing human processes.
-
Do not expect autonomy from GenAI, and do not cede to it your own autonomy of judgment.
-
Practice continual skepticism, treat models’ outputs as speculative fictions, not facts.
We see opportunities for GenAI models when we can hold their outputs lightly, putting them through a process of translation and reinterpretation. Using AI to do one step at a time, in parallel and in combination with human researchers, may surface new insights without putting too much focus on forcing the models to deliver the “right” output. And parallel independent generation—for instance, coming up with a list of ideas yourself and then prompting the model to come up with one—reduces the risk of blind over trust or fixation bias.
Instead of treating LLMs like customers, like experts, or like analysts, treating them as mere generators of text frees us from the presumption that what they write should be true or even intrinsically meaningful. Granted, it takes continual effort to avoid of falling prey to illusions and short-cutting, and to push beyond the literal outputs into all the gaps that the text leaves unexplored. But just talking to something, and trying to critique the text that comes back, can un-block thought and spark insight about what next step to take. You would not trust another being—another human, your dog, a tree—to write a paper, or to analyze data for you, in the way that you would. But situated experiences with those beings can spark surprising insights that contribute to the task at hand.
About the Authors
We are multidisciplinary social researchers and engineers working for Nissan’s Advanced Technology Center Silicon Valley at the intersection of humans and AI in the automotive field. We design and build new automotive experiences, and conduct user research to determine the value of said experiences to humans in various domains—including entertainment, productivity, and safety.
Erik St. Gray (née Stayton) is a social researcher and systems designer with nearly a decade of experience in the automotive industry. He received his Ph.D. from MIT in History, Anthropology, and Science, Technology, and Society (HASTS), and he continues to be driven by curiosity about how incorporate automation in ways that support human flourishing
Kevin Kochever studied computer then behavioral sciences at San José State University, later returning to get his master’s degree in applied anthropology, writing his thesis on the peculiarities of the global smart city phenomenon. He is a lifelong enthusiast of technology and finds endless fascination in observing the interaction between humans and their technologies.
Niloofar Zarei received her PhD in computer science from Texas A&M University, with a focus on human-computer interaction and applied AI. She is driven by a deep curiosity about how intelligent systems can shape human creativity, collaboration, and well-being. Her work bridges technical innovation, from building multimodal AI systems that sense emotion and context, to human-centered research, exploring how we can design agents that are empathetic, engaging, and meaningful in people’s lives.
Research Ethics
For the one discussed study for which we recruited human participants from outside of our organization, we handled recruiting through a third-party agency. All participants signed a disclosure ensuring informed consent. We treated their data and privacy with respect, encrypting research data and ensuring anonymization in any published research. We compensated them for their time. We followed the same handling processes for all internal research subjects, except for study compensation. All research practices were reviewed within our organization by a panel of the study researchers and other researchers not affiliated with the study.
Apart from our uses of AI in research as disclosed in this paper, we did not use AI to contribute to this paper except to generate aliases for our (already AI-generated) virtual personas.
By “persona” we mean a role that the model is placed in, in some cases a character we ask it to play, along with certain additional affordances and inputs necessary for that role. The personas stand for multiple configurations of prompts, languages models, and ways of interacting that we as users may apply toward the tasks that are appropriate for that role: such as generating user journeys, for the mock customer persona. This usage of the term is apt because role-playing is a key affordance of interaction with LLMs and is a common part of prompt engineering to try to achieve desired outputs.
Note also that the models seem to regurgitate some cultural stereotypes—the husband is the family member described as being “analytical.”